publications
2025
- VarDial
 Large Language Models as a Normalizer for Transliteration and Dialectal TranslationMd Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects Code here , Jan 2025
Large Language Models as a Normalizer for Transliteration and Dialectal TranslationMd Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects Code here , Jan 2025NLP models trained on standardized language data often struggle with variations. We assess various Large Language Models (LLMs) for transliteration and dialectal normalization. Tuning open-source LLMs with as little as 10,000 parallel examples using LoRA can achieve results comparable to or better than closed-source LLMs. We perform dialectal normalization experiments for twelve South Asian languages and dialectal translation experiments for six language continua worldwide. The dialectal normalization task can also be a preliminary step for the downstream dialectal translation task. Among the six languages used in dialectal translation, our approach enables Italian and Swiss German to surpass the baseline model by 21.5 and 25.8 BLEU points, respectively.
@inproceedings{alam-anastasopoulos-2025-large, title = {Large Language Models as a Normalizer for Transliteration and Dialectal Translation}, author = {Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Scherrer, Yves and Jauhiainen, Tommi and Ljube{\v{s}}i{\'c}, Nikola and Nakov, Preslav and Tiedemann, Jorg and Zampieri, Marcos}, booktitle = {Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects}, month = jan, year = {2025}, address = {Abu Dhabi, UAE}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.vardial-1.5/}, pages = {39--67}, } - VarDialTesting the Boundaries of LLMs: Dialectal and Language-Variety TasksFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects Code here , Jan 2025
This study evaluates the performance of large language models (LLMs) on benchmark datasets designed for dialect-specific NLP tasks. Dialectal NLP is a low-resource field, yet it is crucial for evaluating the robustness of language models against linguistic diversity. This work is the first to systematically compare state-of-the-art instruction-tuned LLMs—both open-weight multilingual and closed-weight generative models—with encoder-based models that rely on supervised task-specific fine-tuning for dialectal tasks. We conduct extensive empirical analyses to provide insights into the current LLM landscape for dialect-focused tasks. Our findings indicate that certain tasks, such as dialect identification, are challenging for LLMs to replicate effectively due to the complexity of multi-class setups and the suitability of these tasks for supervised fine-tuning. Additionally, the structure of task labels—whether categorical or continuous scoring—significantly affects model performance. While LLMs excel in tasks like machine reading comprehension, their instruction-following ability declines in simpler tasks like POS tagging when task instructions are inherently complex. Overall, subtle variations in prompt design can greatly impact performance, underscoring the need for careful prompt engineering in dialectal evaluations.
@inproceedings{faisal-anastasopoulos-2025-testing, title = {Testing the Boundaries of {LLM}s: Dialectal and Language-Variety Tasks}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Scherrer, Yves and Jauhiainen, Tommi and Ljube{\v{s}}i{\'c}, Nikola and Nakov, Preslav and Tiedemann, Jorg and Zampieri, Marcos}, booktitle = {Proceedings of the 12th Workshop on NLP for Similar Languages, Varieties and Dialects}, month = jan, year = {2025}, address = {Abu Dhabi, UAE}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.vardial-1.6/}, pages = {68--92}, } - ALP
 Towards Ancient Meroitic Decipherment: A Computational ApproachJoshua N. Otten, and Antonios AnastasopoulosIn Proceedings of the Second Workshop on Ancient Language Processing, May 2025
Towards Ancient Meroitic Decipherment: A Computational ApproachJoshua N. Otten, and Antonios AnastasopoulosIn Proceedings of the Second Workshop on Ancient Language Processing, May 2025The discovery of the Rosetta Stone was one of the keys that helped unlock the secrets of Ancient Egypt and its hieroglyphic language. But what about languages with no such ’Rosetta Stone?’ Meroitic is an ancient language from what is now present-day Sudan, but even though it is connected to Egyptian in many ways, much of its grammar and vocabulary remains undeciphered. In this work, we introduce the challenge of Meroitic decipherment as a computational task, and present the first Meroitic machine-readable corpus. We then train embeddings and perform intrinsic evaluations, as well as cross-lingual alignment experiments between Meroitic and Late-Egyptian. We conclude by outlining open problems and potential research directions.
@inproceedings{otten-anastasopoulos-2025-towards, title = {Towards {A}ncient {M}eroitic Decipherment: A Computational Approach}, author = {Otten, Joshua N. and Anastasopoulos, Antonios}, editor = {Anderson, Adam and Gordin, Shai and Li, Bin and Liu, Yudong and Passarotti, Marco C. and Sprugnoli, Rachele}, booktitle = {Proceedings of the Second Workshop on Ancient Language Processing}, month = may, year = {2025}, address = {The Albuquerque Convention Center, Laguna}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.alp-1.11/}, pages = {87--98}, isbn = {979-8-89176-235-0}, } - NAACL
 mHumanEval - A Multilingual Benchmark to Evaluate Large Language Models for Code GenerationMd Nishat Raihan, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025
mHumanEval - A Multilingual Benchmark to Evaluate Large Language Models for Code GenerationMd Nishat Raihan, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025@inproceedings{raihan-etal-2025-mhumaneval, title = {m{H}uman{E}val - A Multilingual Benchmark to Evaluate Large Language Models for Code Generation}, author = {Raihan, Md Nishat and Anastasopoulos, Antonios and Zampieri, Marcos}, editor = {Chiruzzo, Luis and Ritter, Alan and Wang, Lu}, booktitle = {Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, month = apr, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.naacl-long.570/}, pages = {11432--11461}, isbn = {979-8-89176-189-6}, } - NAACL
 Follow the Beaten Path: The Role of Route Patterns on Vision-Language Navigation Agents Generalization AbilitiesKourosh T Baghaei, Dieter Pfoser, and Antonios AnastasopoulosIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025
Follow the Beaten Path: The Role of Route Patterns on Vision-Language Navigation Agents Generalization AbilitiesKourosh T Baghaei, Dieter Pfoser, and Antonios AnastasopoulosIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025@inproceedings{baghaei-etal-2025-follow, title = {Follow the Beaten Path: The Role of Route Patterns on Vision-Language Navigation Agents Generalization Abilities}, author = {Baghaei, Kourosh T and Pfoser, Dieter and Anastasopoulos, Antonios}, editor = {Chiruzzo, Luis and Ritter, Alan and Wang, Lu}, booktitle = {Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, month = apr, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.naacl-long.406/}, pages = {7986--8005}, isbn = {979-8-89176-189-6}, } - NAACL
 Script-Agnosticism and its Impact on Language Identification for Dravidian LanguagesMilind Agarwal, Joshua Otten, and Antonios AnastasopoulosIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025
Script-Agnosticism and its Impact on Language Identification for Dravidian LanguagesMilind Agarwal, Joshua Otten, and Antonios AnastasopoulosIn Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Code here , Apr 2025@inproceedings{agarwal-etal-2025-script, title = {Script-Agnosticism and its Impact on Language Identification for {D}ravidian Languages}, author = {Agarwal, Milind and Otten, Joshua and Anastasopoulos, Antonios}, editor = {Chiruzzo, Luis and Ritter, Alan and Wang, Lu}, booktitle = {Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, month = apr, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.naacl-long.377/}, pages = {7364--7384}, isbn = {979-8-89176-189-6}, } - WACV
 Crossroads of Continents: Automated Artifact Extraction for Cultural Adaptation with Large Multimodal ModelsAnjishnu Mukherjee, Ziwei Zhu, and Antonios AnastasopoulosIn 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Code here , Feb 2025
Crossroads of Continents: Automated Artifact Extraction for Cultural Adaptation with Large Multimodal ModelsAnjishnu Mukherjee, Ziwei Zhu, and Antonios AnastasopoulosIn 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Code here , Feb 2025We present a comprehensive three-phase study to ex-amine (1) the cultural understanding of Large Multimodal Models (LMMs) by introducing Dalle Street, a large-scale dataset generated by DALL-E 3 and validated by hu-mans, containing 9, 935 images of 67 countries and 10 concept classes, (2) the underlying implicit and potentially stereotypical cultural associations with a cultural artifact extraction task, and (3) an approach to adapt cultural representation in an image based on extracted associations using a modular pipeline, Cultureadapt. We find disparities in cultural understanding at geographic sub-region levels with both open-source (LLaVA) and closed-source (GPT-4V) models on Dalle Street and other existing benchmarks, which we try to understand using over 18, 000 artifacts that we identify in association to different coun-tries. Our findings reveal a nuanced picture of the cultural competence of LMMs, highlighting the need to develop culture-aware systems.11Dataset and code are available: https://github.com/iamshnoo/crossroads
@inproceedings{mukherjee-etal-2025-crossroads, author = {Mukherjee, Anjishnu and Zhu, Ziwei and Anastasopoulos, Antonios}, booktitle = {2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)}, title = {Crossroads of Continents: Automated Artifact Extraction for Cultural Adaptation with Large Multimodal Models}, year = {2025}, volume = {}, number = {}, pages = {1755-1764}, keywords = {Cultural competence;Adaptation models;Computer vision;Codes;Computational modeling;Pipelines;Benchmark testing;Cultural differences;Continents;Artificial intelligence;cultural localization;cultural bias analysis;llm;multimodal;culture;dataset}, doi = {10.1109/WACV61041.2025.00178}, issn = {2642-9381}, month = feb, } - AmericasNLPMachine Translation Metrics for Indigenous Languages Using Fine-tuned Semantic EmbeddingsNathaniel Krasner*, Justin Vasselli*, Belu Ticona, Antonios Anastasopoulos, and Chi-Kiu LoIn Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP) Code here , May 2025
@inproceedings{krasner-etal-2025-machine, title = {Machine Translation Metrics for Indigenous Languages Using Fine-tuned Semantic Embeddings}, author = {Krasner, Nathaniel and Vasselli, Justin and Ticona, Belu and Anastasopoulos, Antonios and Lo, Chi-Kiu}, editor = {Mager, Manuel and Ebrahimi, Abteen and Pugh, Robert and Rijhwani, Shruti and Von Der Wense, Katharina and Chiruzzo, Luis and Coto-Solano, Rolando and Oncevay, Arturo}, booktitle = {Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP)}, month = may, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.americasnlp-1.11/}, pages = {100--104}, isbn = {979-8-89176-236-7}, } - AmericasNLPMachine Translation Using Grammar Materials for LLM Post-CorrectionJonathan Hus, Antonios Anastasopoulos, and Nathaniel KrasnerIn Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP) Code here , May 2025
@inproceedings{hus-etal-2025-machine, title = {Machine Translation Using Grammar Materials for {LLM} Post-Correction}, author = {Hus, Jonathan and Anastasopoulos, Antonios and Krasner, Nathaniel}, editor = {Mager, Manuel and Ebrahimi, Abteen and Pugh, Robert and Rijhwani, Shruti and Von Der Wense, Katharina and Chiruzzo, Luis and Coto-Solano, Rolando and Oncevay, Arturo}, booktitle = {Proceedings of the Fifth Workshop on NLP for Indigenous Languages of the Americas (AmericasNLP)}, month = may, year = {2025}, address = {Albuquerque, New Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.americasnlp-1.10/}, pages = {92--99}, isbn = {979-8-89176-236-7}, } - ACL
 Cross-Lingual Representation Alignment Through Contrastive Image-Caption TuningNathaniel Krasner, Nicholas Lanuzo, and Antonios AnastasopoulosIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) Code here , Jul 2025
Cross-Lingual Representation Alignment Through Contrastive Image-Caption TuningNathaniel Krasner, Nicholas Lanuzo, and Antonios AnastasopoulosIn Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) Code here , Jul 2025@inproceedings{krasner-etal-2025-cross, title = {Cross-Lingual Representation Alignment Through Contrastive Image-Caption Tuning}, author = {Krasner, Nathaniel and Lanuzo, Nicholas and Anastasopoulos, Antonios}, editor = {Che, Wanxiang and Nabende, Joyce and Shutova, Ekaterina and Pilehvar, Mohammad Taher}, booktitle = {Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.acl-short.95/}, doi = {10.18653/v1/2025.acl-short.95}, pages = {1193--1199}, isbn = {979-8-89176-252-7}, } - BEACosts and Benefits of AI-Enabled Topic Modeling in P-20 Research: The Case of School Improvement PlansSyeda Sabrina Akter, Seth Hunter, David Woo, and Antonios AnastasopoulosIn Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025) Code here , Jul 2025
@inproceedings{akter-etal-2025-costs, title = {Costs and Benefits of {AI}-Enabled Topic Modeling in {P}-20 Research: The Case of School Improvement Plans}, author = {Akter, Syeda Sabrina and Hunter, Seth and Woo, David and Anastasopoulos, Antonios}, editor = {Kochmar, Ekaterina and Alhafni, Bashar and Bexte, Marie and Burstein, Jill and Horbach, Andrea and Laarmann-Quante, Ronja and Tack, Ana{\"i}s and Yaneva, Victoria and Yuan, Zheng}, booktitle = {Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025)}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.bea-1.34/}, doi = {10.18653/v1/2025.bea-1.34}, pages = {460--476}, isbn = {979-8-89176-270-1}, } - IWSLT
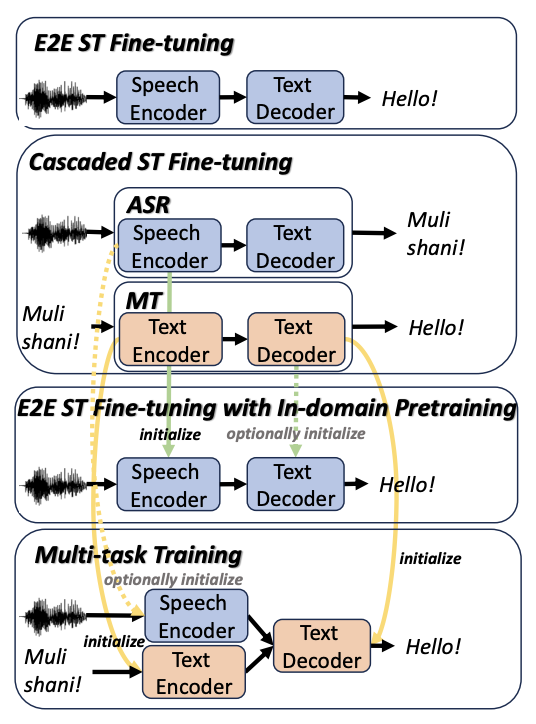 GMU Systems for the IWSLT 2025 Low-Resource Speech Translation Shared TaskChutong Meng, and Antonios AnastasopoulosIn Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025) Code here , Jul 2025
GMU Systems for the IWSLT 2025 Low-Resource Speech Translation Shared TaskChutong Meng, and Antonios AnastasopoulosIn Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025) Code here , Jul 2025This paper describes the GMU systems for the IWSLT 2025 low-resource speech translation shared task. We trained systems for all language pairs, except for Levantine Arabic. We fine-tuned SeamlessM4T-v2 for automatic speech recognition (ASR), machine translation (MT), and end-to-end speech translation (E2E ST). The ASR and MT models are also used to form cascaded ST systems. Additionally, we explored various training paradigms for E2E ST fine-tuning, including direct E2E fine-tuning, multi-task training, and parameter initialization using components from fine-tuned ASR and/or MT models. Our results show that (1) direct E2E fine-tuning yields strong results; (2) initializing with a fine-tuned ASR encoder improves ST performance on languages SeamlessM4T-v2 has not been trained on; (3) multi-task training can be slightly helpful.
@inproceedings{meng-anastasopoulos-2025-gmu, title = {{GMU} Systems for the {IWSLT} 2025 Low-Resource Speech Translation Shared Task}, author = {Meng, Chutong and Anastasopoulos, Antonios}, editor = {Salesky, Elizabeth and Federico, Marcello and Anastasopoulos, Antonis}, booktitle = {Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025)}, month = jul, year = {2025}, address = {Vienna, Austria (in-person and online)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.iwslt-1.29/}, doi = {10.18653/v1/2025.iwslt-1.29}, pages = {289--300}, isbn = {979-8-89176-272-5}, } - UDW
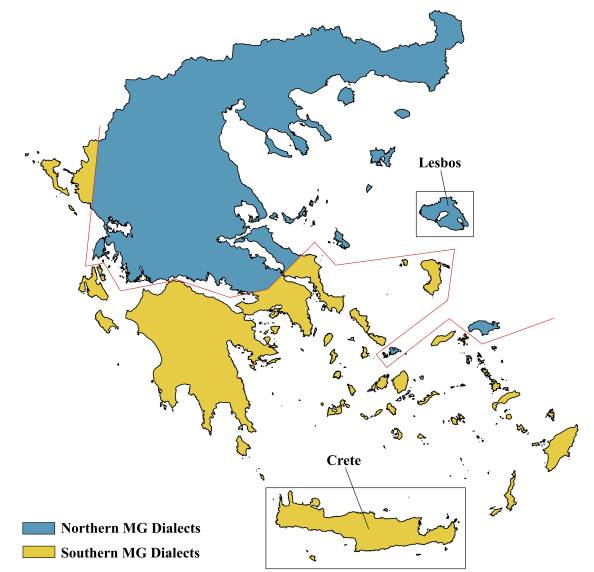 Crossing Dialectal Boundaries: Building a Treebank for the Dialect of Lesbos through Knowledge Transfer from Standard Modern GreekStavros Bompolas, Stella Markantonatou, Angela Ralli, and Antonios AnastasopoulosIn Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025), Aug 2025
Crossing Dialectal Boundaries: Building a Treebank for the Dialect of Lesbos through Knowledge Transfer from Standard Modern GreekStavros Bompolas, Stella Markantonatou, Angela Ralli, and Antonios AnastasopoulosIn Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025), Aug 2025This paper presents the first treebank for the dialect of Lesbos, a low-resource living Northern variety of Modern Greek (MG), annotated according to the Universal Dependencies (UD) framework. So far, the only dialectal treebank available for Greek developed with cross-dialectal knowledge transfer is an East Cretan one, which belongs to the same Southern branch as Standard Modern Greek (SMG). Our study investigates the effectiveness of cross-dialectal knowledge transfer between dialectologically less similar varieties of the same language by leveraging knowledge from SMG to annotate the Northern dialect of Lesbos. We describe the annotation process, present the resulting treebank, inject additional linguistic knowledge to enhance the results, and evaluate the effectiveness of cross-dialectal knowledge transfer for active annotation. Our findings contribute to a better understanding of how dialectal variation within language families affects knowledge transfer in the UD framework, with implications for other low-resource varieties.
@inproceedings{bompolas-etal-2025-crossing, title = {Crossing Dialectal Boundaries: Building a Treebank for the Dialect of Lesbos through Knowledge Transfer from Standard {M}odern {G}reek}, author = {Bompolas, Stavros and Markantonatou, Stella and Ralli, Angela and Anastasopoulos, Antonios}, editor = {Bomma, Gosse and {\c{C}}{\"o}ltekin, {\c{C}}a{\u{g}}r{\i}}, booktitle = {Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025)}, month = aug, year = {2025}, address = {Ljubljana, Slovenia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.udw-1.5/}, pages = {39--51}, isbn = {979-8-89176-292-3}, } - MWEVMWE identification with models trained on GUD (a UDv.2 treebank of Standard Modern Greek)Stella Markantonatou, Vivian Stamou, Stavros Bompolas, Katerina Anastasopoulou, Irianna Linardaki Vasileiadi, Konstantinos Diamantopoulos, Yannis Kazos, and Antonios AnastasopoulosIn Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025), May 2025
UD_Greek-GUD (GUD) is the most recent Universal Dependencies (UD) treebank for Standard Modern Greek (SMG) and the first SMG UD treebank to annotate Verbal Multiword Expressions (VMWEs). GUD contains material from fiction texts and various sites that use colloquial SMG. We describe the special annotation decisions we implemented with GUD, the pipeline we developed to facilitate the active annotation of new material, and we report on the method we designed to evaluate the performance of models trained on GUD as regards VMWE identification tasks.
@inproceedings{markantonatou-etal-2025-vmwe, title = {{VMWE} identification with models trained on {GUD} (a {UD}v.2 treebank of Standard {M}odern {G}reek)}, author = {Markantonatou, Stella and Stamou, Vivian and Bompolas, Stavros and Anastasopoulou, Katerina and Vasileiadi, Irianna Linardaki and Diamantopoulos, Konstantinos and Kazos, Yannis and Anastasopoulos, Antonios}, editor = {Ojha, Atul Kr. and Giouli, Voula and Mititelu, Verginica Barbu and Constant, Mathieu and Korvel, Gra{\v{z}}ina and Do{\u{g}}ru{\"o}z, A. Seza and Rademaker, Alexandre}, booktitle = {Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025)}, month = may, year = {2025}, address = {Albuquerque, New Mexico, U.S.A.}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.mwe-1.3/}, doi = {10.18653/v1/2025.mwe-1.3}, pages = {14--20}, isbn = {979-8-89176-243-5}, } - IWSLTFindings of the IWSLT 2025 Evaluation CampaignIdris Abdulmumin, Victor Agostinelli, Tanel Alumäe, Antonios Anastasopoulos, Luisa Bentivogli, Ondřej Bojar, Claudia Borg, Fethi Bougares, Roldano Cattoni, Mauro Cettolo, and 42 more authorsIn Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025), Jul 2025
This paper presents the outcomes of the shared tasks conducted at the 22nd International Workshop on Spoken Language Translation (IWSLT). The workshop addressed seven critical challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, model compression, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks garnered significant participation, with 32 teams submitting their runs. The field’s growing importance is reflected in the increasing diversity of shared task organizers and contributors to this overview paper, representing a balanced mix of industrial and academic institutions. This broad participation demonstrates the rising prominence of spoken language translation in both research and practical applications.
@inproceedings{agostinelli-etal-2025-findings, title = {Findings of the {IWSLT} 2025 Evaluation Campaign}, author = {Abdulmumin, Idris and Agostinelli, Victor and Alum{\"a}e, Tanel and Anastasopoulos, Antonios and Bentivogli, Luisa and Bojar, Ond{\v{r}}ej and Borg, Claudia and Bougares, Fethi and Cattoni, Roldano and Cettolo, Mauro and Chen, Lizhong and Chen, William and Dabre, Raj and Est{\`e}ve, Yannick and Federico, Marcello and Fishel, Mark and Gaido, Marco and Javorsk{\'y}, D{\'a}vid and Kasztelnik, Marek and Kponou, Fortun{\'e} and Krubi{\'n}ski, Mateusz and Kin Lam, Tsz and Liu, Danni and Matusov, Evgeny and Kumar Maurya, Chandresh and P. McCrae, John and Mdhaffar, Salima and Moslem, Yasmin and Murray, Kenton and Nakamura, Satoshi and Negri, Matteo and Niehues, Jan and Kr. Ojha, Atul and Ortega, John E. and Papi, Sara and Pecina, Pavel and Pol{\'a}k, Peter and Po{\l}e{\'c}, Piotr and Sankar, Ashwin and Savoldi, Beatrice and Sethiya, Nivedita and Sikasote, Claytone and Sperber, Matthias and St{\"u}ker, Sebastian and Sudoh, Katsuhito and Thompson, Brian and Turchi, Marco and Waibel, Alex and Wilken, Patrick and Zevallos, Rodolfo and Zouhar, Vil{\'e}m and Z{\"u}fle, Maike}, editor = {Salesky, Elizabeth and Federico, Marcello and Anastasopoulos, Antonis}, booktitle = {Proceedings of the 22nd International Conference on Spoken Language Translation (IWSLT 2025)}, month = jul, year = {2025}, address = {Vienna, Austria (in-person and online)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.iwslt-1.44/}, doi = {10.18653/v1/2025.iwslt-1.44}, pages = {412--481}, isbn = {979-8-89176-272-5}, } - ACL
 Dialect Normalization using Large Language Models and Morphological RulesAntonios Dimakis, John Pavlopoulos, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2025, Jul 2025
Dialect Normalization using Large Language Models and Morphological RulesAntonios Dimakis, John Pavlopoulos, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2025, Jul 2025@inproceedings{dimakis-etal-2025-dialect, title = {Dialect Normalization using Large Language Models and Morphological Rules}, author = {Dimakis, Antonios and Pavlopoulos, John and Anastasopoulos, Antonios}, editor = {Che, Wanxiang and Nabende, Joyce and Shutova, Ekaterina and Pilehvar, Mohammad Taher}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2025}, month = jul, year = {2025}, address = {Vienna, Austria}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2025.findings-acl.1215/}, doi = {10.18653/v1/2025.findings-acl.1215}, pages = {23696--23714}, isbn = {979-8-89176-256-5}, } - InterspeechSLP Sidekick: An Open-Source, Multilingual Speech Therapy PlatformSam Blouir, Celeste Watkins, Milind Agarwal, Poorvi Acharya, Belu Ticona, Defne Circi, Flavia Negrete, Staci Chan, Jonathan Mbuya Kabala, Syeda Sabrina Akter, and 1 more authorIn Proc. Interspeech 2025, Jul 2025
@inproceedings{blouir2025slp, title = {SLP Sidekick: An Open-Source, Multilingual Speech Therapy Platform}, author = {Blouir, Sam and Watkins, Celeste and Agarwal, Milind and Acharya, Poorvi and Ticona, Belu and Circi, Defne and Negrete, Flavia and Chan, Staci and Kabala, Jonathan Mbuya and Akter, Syeda Sabrina and others}, booktitle = {Proc. Interspeech 2025}, pages = {4971--4972}, year = {2025}, }










2024
- ACL
 DIALECTBENCH: An NLP Benchmark for Dialects, Varieties, and Closely-Related LanguagesFahim Faisal*, Orevaoghene Ahia*, Aarohi Srivastava*, Kabir Ahuja, David Chiang, Yulia Tsvetkov, and Antonios AnastasopoulosIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) code here , Aug 2024
DIALECTBENCH: An NLP Benchmark for Dialects, Varieties, and Closely-Related LanguagesFahim Faisal*, Orevaoghene Ahia*, Aarohi Srivastava*, Kabir Ahuja, David Chiang, Yulia Tsvetkov, and Antonios AnastasopoulosIn Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) code here , Aug 2024Societal Impact Award
Language technologies should be judged on their usefulness in real-world use cases. An often overlooked aspect in natural language processing (NLP) research and evaluation is language variation in the form of non-standard dialects or language varieties (hereafter, varieties). Most NLP benchmarks are limited to standard language varieties. To fill this gap, we propose DIALECTBENCH, the first-ever large-scale benchmark for NLP on varieties, which aggregates an extensive set of task-varied varieties datasets (10 text-level tasks covering 281 varieties). This allows for a comprehensive evaluation of NLP system performance on different varieties. We provide substantial proof of performance disparities between standard and non-standard language varieties, and we also identify language clusters with larger performance divergence across tasks.We believe DIALECTBENCH provides a comprehensive view of the current state of NLP for varieties and one step towards advancing it further.
@inproceedings{faisal-etal-2024-dialectbench, title = {{DIALECTBENCH}: An {NLP} Benchmark for Dialects, Varieties, and Closely-Related Languages}, author = {Faisal, Fahim and Ahia, Orevaoghene and Srivastava, Aarohi and Ahuja, Kabir and Chiang, David and Tsvetkov, Yulia and Anastasopoulos, Antonios}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.acl-long.777/}, doi = {10.18653/v1/2024.acl-long.777}, pages = {14412--14454}, } - AmericasNLP
 A Concise Survey of OCR for Low-Resource LanguagesMilind Agarwal, and Antonios AnastasopoulosIn Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024) code here , Jun 2024
A Concise Survey of OCR for Low-Resource LanguagesMilind Agarwal, and Antonios AnastasopoulosIn Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024) code here , Jun 2024Modern natural language processing (NLP) techniques increasingly require substantial amounts of data to train robust algorithms. Building such technologies for low-resource languages requires focusing on data creation efforts and data-efficient algorithms. For a large number of low-resource languages, especially Indigenous languages of the Americas, this data exists in image-based non-machine-readable documents. This includes scanned copies of comprehensive dictionaries, linguistic field notes, children‘s stories, and other textual material. To digitize these resources, Optical Character Recognition (OCR) has played a major role but it comes with certain challenges in low-resource settings. In this paper, we share the first survey of OCR techniques specific to low-resource data creation settings and outline several open challenges, with a special focus on Indigenous Languages of the Americas. Based on experiences and results from previous research, we conclude with recommendations on utilizing and improving OCR for the benefit of computational researchers, linguists, and language communities.
@inproceedings{agarwal-anastasopoulos-2024-concise, title = {A Concise Survey of {OCR} for Low-Resource Languages}, author = {Agarwal, Milind and Anastasopoulos, Antonios}, editor = {Mager, Manuel and Ebrahimi, Abteen and Rijhwani, Shruti and Oncevay, Arturo and Chiruzzo, Luis and Pugh, Robert and von der Wense, Katharina}, booktitle = {Proceedings of the 4th Workshop on Natural Language Processing for Indigenous Languages of the Americas (AmericasNLP 2024)}, month = jun, year = {2024}, address = {Mexico City, Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.americasnlp-1.10/}, doi = {10.18653/v1/2024.americasnlp-1.10}, pages = {88--102}, } - ClimateNLP
 Unlearning Climate Misinformation in Large Language ModelsMichael Fore, Simranjit Singh, Chaehong Lee, Amritanshu Pandey, Antonios Anastasopoulos, and Dimitrios StamoulisIn Proceedings of the 1st Workshop on Natural Language Processing Meets Climate Change (ClimateNLP 2024), Aug 2024
Unlearning Climate Misinformation in Large Language ModelsMichael Fore, Simranjit Singh, Chaehong Lee, Amritanshu Pandey, Antonios Anastasopoulos, and Dimitrios StamoulisIn Proceedings of the 1st Workshop on Natural Language Processing Meets Climate Change (ClimateNLP 2024), Aug 2024Misinformation regarding climate change is a key roadblock in addressing one of the most serious threats to humanity. This paper investigates factual accuracy in large language models (LLMs) regarding climate information. Using true/false labeled Q&A data for fine-tuning and evaluating LLMs on climate-related claims, we compare open-source models, assessing their ability to generate truthful responses to climate change questions. We investigate the detectability of models intentionally poisoned with false climate information, finding that such poisoning may not affect the accuracy of a model‘s responses in other domains. Furthermore, we compare the effectiveness of unlearning algorithms, fine-tuning, and Retrieval-Augmented Generation (RAG) for factually grounding LLMs on climate change topics. Our evaluation reveals that unlearning algorithms can be effective for nuanced conceptual claims, despite previous findings suggesting their inefficacy in privacy contexts. These insights aim to guide the development of more factually reliable LLMs and highlight the need for additional work to secure LLMs against misinformation attacks.
@inproceedings{fore-etal-2024-unlearning, title = {Unlearning Climate Misinformation in Large Language Models}, author = {Fore, Michael and Singh, Simranjit and Lee, Chaehong and Pandey, Amritanshu and Anastasopoulos, Antonios and Stamoulis, Dimitrios}, editor = {Stammbach, Dominik and Ni, Jingwei and Schimanski, Tobias and Dutia, Kalyan and Singh, Alok and Bingler, Julia and Christiaen, Christophe and Kushwaha, Neetu and Muccione, Veruska and A. Vaghefi, Saeid and Leippold, Markus}, booktitle = {Proceedings of the 1st Workshop on Natural Language Processing Meets Climate Change (ClimateNLP 2024)}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.climatenlp-1.14/}, doi = {10.18653/v1/2024.climatenlp-1.14}, pages = {178--192}, } - EMNLP
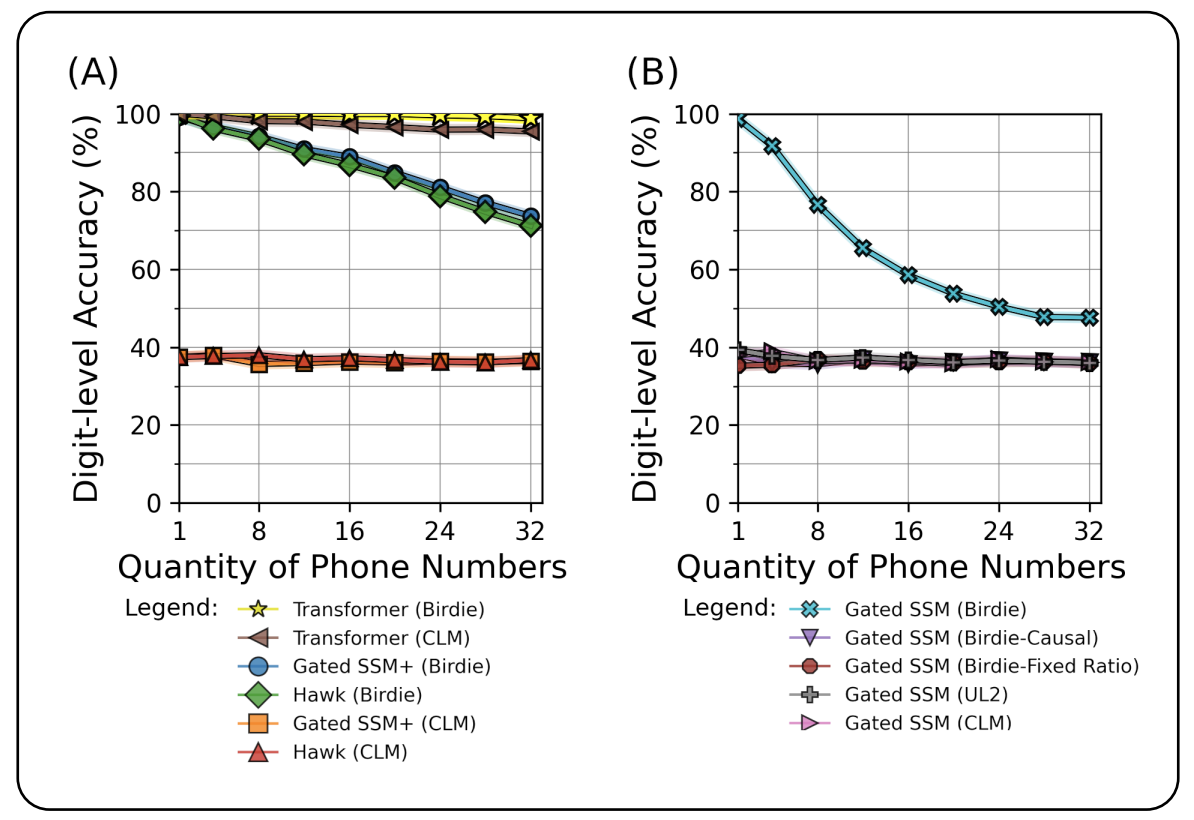 Birdie: Advancing State Space Language Modeling with Dynamic Mixtures of Training ObjectivesSam Blouir, Jimmy T.h. Smith, Antonios Anastasopoulos, and Amarda ShehuIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024
Birdie: Advancing State Space Language Modeling with Dynamic Mixtures of Training ObjectivesSam Blouir, Jimmy T.h. Smith, Antonios Anastasopoulos, and Amarda ShehuIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024Efficient state space models (SSMs), including linear recurrent neural networks and linear attention variants, have emerged as potential alternative language models to Transformers. While efficient, SSMs struggle with tasks requiring in-context retrieval, such as text copying and associative recall, limiting their usefulness in practical settings. Prior work on how to meet this challenge has focused on the internal model architecture and not investigated the role of the training procedure. This paper proposes a new training procedure that improve the performance of SSMs on retrieval-intensive tasks. This novel pre-training procedure combines a bidirectional processing of the input with dynamic mixtures of pre-training objectives to improve the utilization of the SSM‘s fixed-size state. Our experimental evaluations show that this procedure significantly improves performance on retrieval-intensive tasks that challenge current SSMs, such as phone book lookup, long paragraph question-answering, and infilling tasks. Our findings offer insights into a new direction to advance the training of SSMs to close the performance gap with Transformers.
@inproceedings{blouir-etal-2024-birdie, title = {Birdie: Advancing State Space Language Modeling with Dynamic Mixtures of Training Objectives}, author = {Blouir, Sam and Smith, Jimmy T.h. and Anastasopoulos, Antonios and Shehu, Amarda}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.541/}, doi = {10.18653/v1/2024.emnlp-main.541}, pages = {9679--9705}, } - EMNLP
 Back to School: Translation Using Grammar BooksJonathan Hus, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024
Back to School: Translation Using Grammar BooksJonathan Hus, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024Machine translation systems for high resource languages perform exceptionally well and produce high quality translations. Unfortunately, the vast majority of languages are not considered high resource and lack the quantity of parallel sentences needed to train such systems. These under-represented languages are not without resources, however, and bilingual dictionaries and grammar books are available as linguistic reference material. With current large language models (LLMs) supporting near book-length contexts, we can begin to use the available material to ensure advancements are shared among all of the world‘s languages. In this paper, we demonstrate incorporating grammar books in the prompt of GPT-4 to improve machine translation and evaluate the performance on 16 topologically diverse low-resource languages, using a combination of reference material to show that the machine translation performance of LLMs can be improved using this method.
@inproceedings{hus-anastasopoulos-2024-back, title = {Back to School: Translation Using Grammar Books}, author = {Hus, Jonathan and Anastasopoulos, Antonios}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.1127/}, doi = {10.18653/v1/2024.emnlp-main.1127}, pages = {20207--20219}, } - EMNLP
 The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?Alexander Choi*, Syeda Sabrina Akter*, J.p. Singh, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024
The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?Alexander Choi*, Syeda Sabrina Akter*, J.p. Singh, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024Large Language Models (LLMs) have shown capabilities close to human performance in various analytical tasks, leading researchers to use them for time and labor-intensive analyses. However, their capability to handle highly specialized and open-ended tasks in domains like policy studies remains in question. This paper investigates the efficiency and accuracy of LLMs in specialized tasks through a structured user study focusing on Human-LLM partnership. The study, conducted in two stages—Topic Discovery and Topic Assignment—integrates LLMs with expert annotators to observe the impact of LLM suggestions on what is usually human-only analysis. Results indicate that LLM-generated topic lists have significant overlap with human generated topic lists, with minor hiccups in missing document-specific topics. However, LLM suggestions may significantly improve task completion speed, but at the same time introduce anchoring bias, potentially affecting the depth and nuance of the analysis, raising a critical question about the trade-off between increased efficiency and the risk of biased analysis.
@inproceedings{choi-etal-2024-llm, title = {The {LLM} Effect: Are Humans Truly Using {LLM}s, or Are They Being Influenced By Them Instead?}, author = {Choi, Alexander and Akter, Syeda Sabrina and Singh, J.p. and Anastasopoulos, Antonios}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.emnlp-main.1230/}, doi = {10.18653/v1/2024.emnlp-main.1230}, pages = {22032--22054}, } - EACL
 CODET: A Benchmark for Contrastive Dialectal Evaluation of Machine TranslationMd Mahfuz Ibn Alam, Sina Ahmadi, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EACL 2024 code here , Mar 2024
CODET: A Benchmark for Contrastive Dialectal Evaluation of Machine TranslationMd Mahfuz Ibn Alam, Sina Ahmadi, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EACL 2024 code here , Mar 2024Neural machine translation (NMT) systems exhibit limited robustness in handling source-side linguistic variations. Their performance tends to degrade when faced with even slight deviations in language usage, such as different domains or variations introduced by second-language speakers. It is intuitive to extend this observation to encompass dialectal variations as well, but the work allowing the community to evaluate MT systems on this dimension is limited. To alleviate this issue, we compile and release CODET, a contrastive dialectal benchmark encompassing 891 different variations from twelve different languages. We also quantitatively demonstrate the challenges large MT models face in effectively translating dialectal variants. All the data and code have been released.
@inproceedings{alam-etal-2024-codet, title = {{CODET}: A Benchmark for Contrastive Dialectal Evaluation of Machine Translation}, author = {Alam, Md Mahfuz Ibn and Ahmadi, Sina and Anastasopoulos, Antonios}, editor = {Graham, Yvette and Purver, Matthew}, booktitle = {Findings of the Association for Computational Linguistics: EACL 2024}, month = mar, year = {2024}, address = {St. Julian{'}s, Malta}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-eacl.125/}, pages = {1790--1859}, } - NAACL
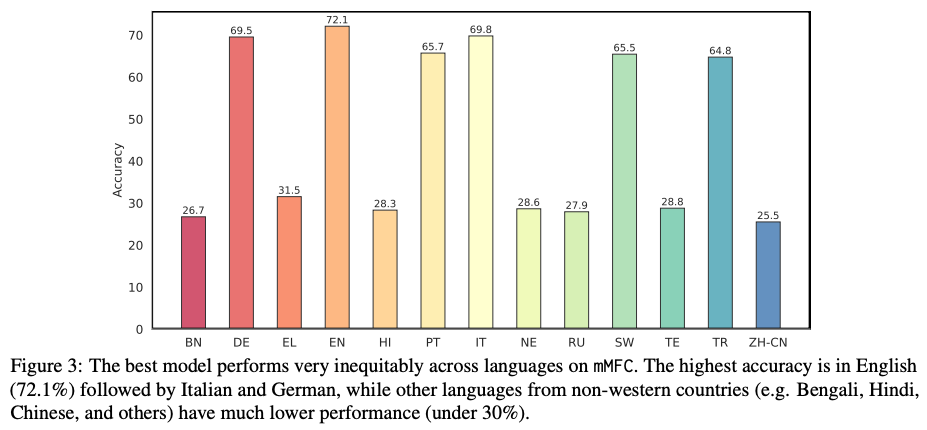 A Study on Scaling Up Multilingual News Framing AnalysisSyeda Sabrina Akter, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: NAACL 2024 code here , Jun 2024
A Study on Scaling Up Multilingual News Framing AnalysisSyeda Sabrina Akter, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: NAACL 2024 code here , Jun 2024Media framing is the study of strategically selecting and presenting specific aspects of political issues to shape public opinion. Despite its relevance to almost all societies around the world, research has been limited due to the lack of available datasets and other resources. This study explores the possibility of dataset creation through crowdsourcing, utilizing non-expert annotators to develop training corpora. We first extend framing analysis beyond English news to a multilingual context (12 typologically diverse languages) through automatic translation. We also present a novel benchmark in Bengali and Portuguese on the immigration and same-sex marriage domains.Additionally, we show that a system trained on our crowd-sourced dataset, combined with other existing ones, leads to a 5.32 percentage point increase from the baseline, showing that crowdsourcing is a viable option. Last, we study the performance of large language models (LLMs) for this task, finding that task-specific fine-tuning is a better approach than employing bigger non-specialized models.
@inproceedings{akter-anastasopoulos-2024-study, title = {A Study on Scaling Up Multilingual News Framing Analysis}, author = {Akter, Syeda Sabrina and Anastasopoulos, Antonios}, editor = {Duh, Kevin and Gomez, Helena and Bethard, Steven}, booktitle = {Findings of the Association for Computational Linguistics: NAACL 2024}, month = jun, year = {2024}, address = {Mexico City, Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-naacl.260/}, doi = {10.18653/v1/2024.findings-naacl.260}, pages = {4156--4173}, } - ACL
 Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource LanguagesAntonios Dimakis, Stella Markantonatou, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2024 code here , Aug 2024
Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource LanguagesAntonios Dimakis, Stella Markantonatou, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2024 code here , Aug 2024Multi-word expressions (MWEs) present unique challenges in natural language processing (NLP), particularly within the context of translation systems, due to their inherent scarcity, non-compositional nature, and other distinct lexical and morphosyntactic characteristics, issues that are exacerbated in low-resource settings.In this study, we elucidate and attempt to address these challenges by leveraging a substantial corpus of human-annotated Greek MWEs. To address the complexity of translating such phrases, we propose a novel method leveraging an available out-of-context lexicon.We assess the translation capabilities of current state-of-the-art systems on this task, employing both automated metrics and human evaluators.We find that by using our method when applicable, the performance of current systems can be significantly improved, however these models are still unable to produce translations comparable to those of a human speaker.
@inproceedings{dimakis-etal-2024-dictionary, title = {Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource Languages}, author = {Dimakis, Antonios and Markantonatou, Stella and Anastasopoulos, Antonios}, editor = {Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2024}, month = aug, year = {2024}, address = {Bangkok, Thailand}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-acl.152/}, doi = {10.18653/v1/2024.findings-acl.152}, pages = {2588--2595}, } - EMNLP
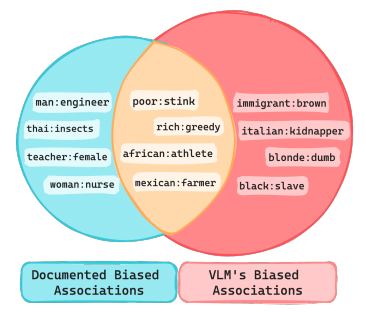 BiasDora: Exploring Hidden Biased Associations in Vision-Language ModelsChahat Raj, Anjishnu Mukherjee, Aylin Caliskan, Antonios Anastasopoulos, and Ziwei ZhuIn Findings of the Association for Computational Linguistics: EMNLP 2024 code here , Nov 2024
BiasDora: Exploring Hidden Biased Associations in Vision-Language ModelsChahat Raj, Anjishnu Mukherjee, Aylin Caliskan, Antonios Anastasopoulos, and Ziwei ZhuIn Findings of the Association for Computational Linguistics: EMNLP 2024 code here , Nov 2024Existing works examining Vision-Language Models (VLMs) for social biases predominantly focus on a limited set of documented bias associations, such as gender-profession or race-crime. This narrow scope often overlooks a vast range of unexamined implicit associations, restricting the identification and, hence, mitigation of such biases. We address this gap by probing VLMs to (1) uncover hidden, implicit associations across 9 bias dimensions. We systematically explore diverse input and output modalities and (2) demonstrate how biased associations vary in their negativity, toxicity, and extremity. Our work (3) identifies subtle and extreme biases that are typically not recognized by existing methodologies. We make the **D**ataset **o**f **r**etrieved **a**ssociations (**Dora**) publicly available.
@inproceedings{raj-etal-2024-biasdora, title = {{B}ias{D}ora: Exploring Hidden Biased Associations in Vision-Language Models}, author = {Raj, Chahat and Mukherjee, Anjishnu and Caliskan, Aylin and Anastasopoulos, Antonios and Zhu, Ziwei}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-emnlp.611/}, doi = {10.18653/v1/2024.findings-emnlp.611}, pages = {10439--10455}, } - EMNLP
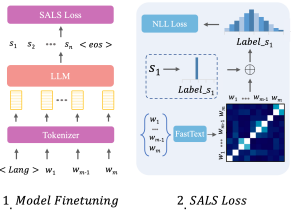 Gloss2Text: Sign Language Gloss translation using LLMs and Semantically Aware Label SmoothingPooya Fayyazsanavi, Antonios Anastasopoulos, and Jana KoseckaIn Findings of the Association for Computational Linguistics: EMNLP 2024 code here , Nov 2024
Gloss2Text: Sign Language Gloss translation using LLMs and Semantically Aware Label SmoothingPooya Fayyazsanavi, Antonios Anastasopoulos, and Jana KoseckaIn Findings of the Association for Computational Linguistics: EMNLP 2024 code here , Nov 2024Sign language translation from video to spoken text presents unique challenges owing to the distinct grammar, expression nuances, and high variation of visual appearance across different speakers and contexts. Gloss annotations serve as an intermediary to guide the translation process. In our work, we focus on \textitGloss2Text translation stage and propose several advances by leveraging pre-trained large language models (LLMs), data augmentation, and novel label-smoothing loss function exploiting gloss translation ambiguities improving significantly the performance of state-of-the-art approaches. Through extensive experiments and ablation studies on the PHOENIX Weather 2014T dataset, our approach surpasses state-of-the-art performance in \textitGloss2Text translation, indicating its efficacy in addressing sign language translation and suggesting promising avenues for future research and development.
@inproceedings{fayyazsanavi-etal-2024-gloss2text, title = {{G}loss2{T}ext: Sign Language Gloss translation using {LLM}s and Semantically Aware Label Smoothing}, author = {Fayyazsanavi, Pooya and Anastasopoulos, Antonios and Kosecka, Jana}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-emnlp.947/}, doi = {10.18653/v1/2024.findings-emnlp.947}, pages = {16162--16171}, } - IWSLTFINDINGS OF THE IWSLT 2024 EVALUATION CAMPAIGNIbrahim Said Ahmad, Antonios Anastasopoulos, Ondřej Bojar, Claudia Borg, Marine Carpuat, Roldano Cattoni, Mauro Cettolo, William Chen, Qianqian Dong, Marcello Federico, and 34 more authorsIn Proceedings of the 21st International Conference on Spoken Language Translation (IWSLT 2024), Aug 2024
This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 17 teams whose submissions are documented in 27 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
@inproceedings{ahmad-etal-2024-findings, title = {{FINDINGS} {OF} {THE} {IWSLT} 2024 {EVALUATION} {CAMPAIGN}}, author = {Ahmad, Ibrahim Said and Anastasopoulos, Antonios and Bojar, Ond{\v{r}}ej and Borg, Claudia and Carpuat, Marine and Cattoni, Roldano and Cettolo, Mauro and Chen, William and Dong, Qianqian and Federico, Marcello and Haddow, Barry and Javorsk{\'y}, D{\'a}vid and Krubi{\'n}ski, Mateusz and Lam, Tsz Kin and Ma, Xutai and Mathur, Prashant and Matusov, Evgeny and Maurya, Chandresh and McCrae, John and Murray, Kenton and Nakamura, Satoshi and Negri, Matteo and Niehues, Jan and Niu, Xing and Ojha, Atul Kr. and Ortega, John and Papi, Sara and Pol{\'a}k, Peter and Posp{\'i}{\v{s}}il, Adam and Pecina, Pavel and Salesky, Elizabeth and Sethiya, Nivedita and Sarkar, Balaram and Shi, Jiatong and Sikasote, Claytone and Sperber, Matthias and St{\"u}ker, Sebastian and Sudoh, Katsuhito and Thompson, Brian and Waibel, Alex and Watanabe, Shinji and Wilken, Patrick and Zem{\'a}nek, Petr and Zevallos, Rodolfo}, editor = {Salesky, Elizabeth and Federico, Marcello and Carpuat, Marine}, booktitle = {Proceedings of the 21st International Conference on Spoken Language Translation (IWSLT 2024)}, month = aug, year = {2024}, address = {Bangkok, Thailand (in-person and online)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.iwslt-1.1/}, doi = {10.18653/v1/2024.iwslt-1.1}, pages = {1--11}, } - LREC-COLING
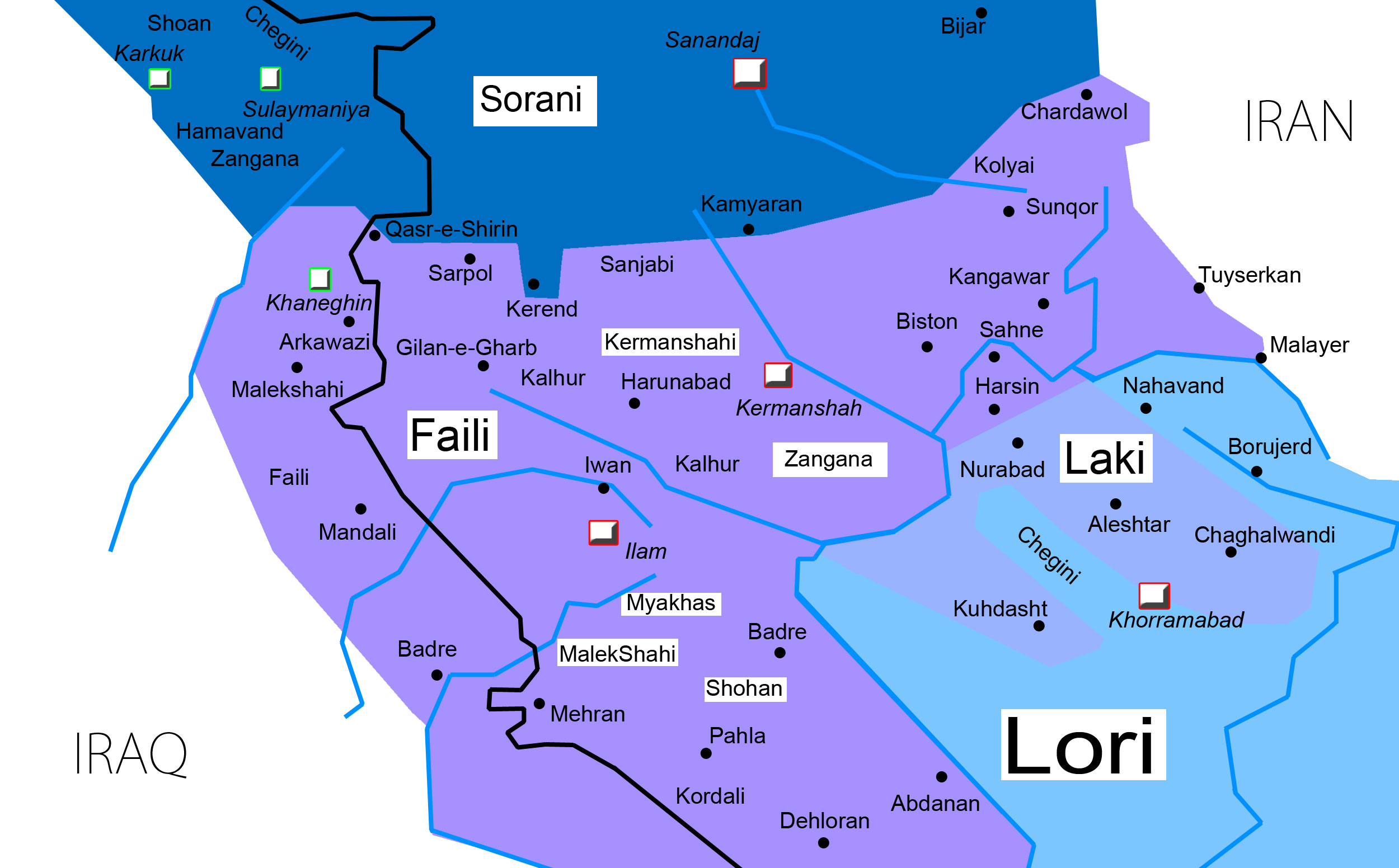 Language and Speech Technology for Central Kurdish VarietiesSina Ahmadi, Daban Jaff, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) code here , May 2024
Language and Speech Technology for Central Kurdish VarietiesSina Ahmadi, Daban Jaff, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) code here , May 2024Kurdish, an Indo-European language spoken by over 30 million speakers, is considered a dialect continuum and known for its diversity in language varieties. Previous studies addressing language and speech technology for Kurdish handle it in a monolithic way as a macro-language, resulting in disparities for dialects and varieties for which there are few resources and tools available. In this paper, we take a step towards developing resources for language and speech technology for varieties of Central Kurdish, creating a corpus by transcribing movies and TV series as an alternative to fieldwork. Additionally, we report the performance of machine translation, automatic speech recognition, and language identification as downstream tasks evaluated on Central Kurdish subdialects. Data and models are publicly available under an open license at https://github.com/sinaahmadi/CORDI.
@inproceedings{ahmadi-etal-2024-language, title = {Language and Speech Technology for {C}entral {K}urdish Varieties}, author = {Ahmadi, Sina and Jaff, Daban and Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Calzolari, Nicoletta and Kan, Min-Yen and Hoste, Veronique and Lenci, Alessandro and Sakti, Sakriani and Xue, Nianwen}, booktitle = {Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)}, month = may, year = {2024}, address = {Torino, Italia}, publisher = {ELRA and ICCL}, url = {https://aclanthology.org/2024.lrec-main.877/}, pages = {10034--10045}, } - MRL
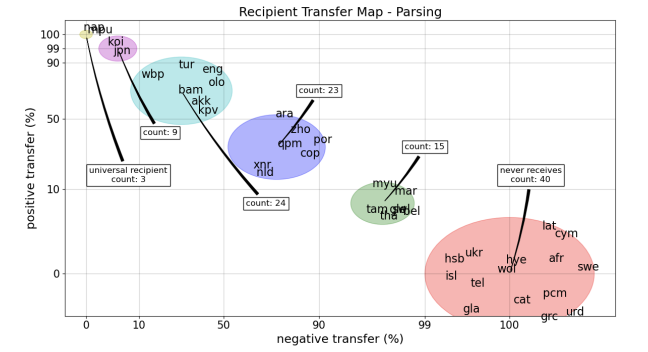 An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language ModelsFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024) code here , Nov 2024
An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language ModelsFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024) code here , Nov 2024The capacity and effectiveness of pre-trained multilingual models (MLMs) for zero-shot cross-lingual transfer is well established. However, phenomena of positive or negative transfer, and the effect of language choice still need to be fully understood, especially in the complex setting of massively multilingual LMs. We propose an \textitefficient method to study transfer language influence in zero-shot performance on another target language. Unlike previous work, our approach \textitdisentangles downstream tasks from language, using dedicated adapter units. Our findings suggest that some languages do not largely affect others, while some languages, especially ones unseen during pre-training, can be extremely beneficial or detrimental for different target languages. We find that no transfer language is beneficial for all target languages. We do, curiously, observe languages previously unseen by MLMs consistently benefit from transfer from \textitalmost any language. We additionally use our modular approach to quantify negative interference efficiently and categorize languages accordingly. Furthermore, we provide a list of promising transfer-target language configurations that consistently lead to target language performance improvements.
@inproceedings{faisal-anastasopoulos-2024-efficient, title = {An Efficient Approach for Studying Cross-Lingual Transfer in Multilingual Language Models}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {S{\"a}lev{\"a}, Jonne and Owodunni, Abraham}, booktitle = {Proceedings of the Fourth Workshop on Multilingual Representation Learning (MRL 2024)}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.mrl-1.4/}, doi = {10.18653/v1/2024.mrl-1.4}, pages = {45--92}, } - NAACL
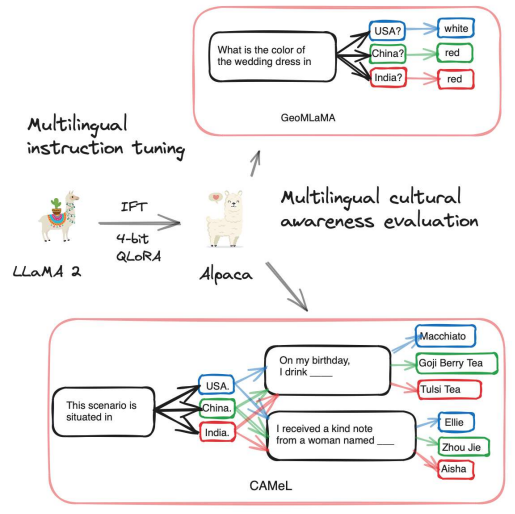 Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction TuningAnjishnu Mukherjee, Aylin Caliskan, Ziwei Zhu, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) code here , Jun 2024
Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction TuningAnjishnu Mukherjee, Aylin Caliskan, Ziwei Zhu, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) code here , Jun 2024Exploring the intersection of language and culture in Large Language Models (LLMs), this study critically examines their capability to encapsulate cultural nuances across diverse linguistic landscapes. Central to our investigation are three research questions: the efficacy of language-specific instruction tuning, the impact of pretraining on dominant language data, and the identification of optimal approaches to elicit accurate cultural knowledge from LLMs. Utilizing the GeoMLaMA benchmark for multilingual commonsense knowledge and an adapted CAMeL dataset (English-only) for evaluation of nuanced cultural aspects, our experiments span six different languages and cultural contexts, revealing the extent of LLMs’ cultural awareness. Our findings highlight a nuanced landscape: while language-specific tuning and bilingual pretraining enhance cultural understanding in certain contexts, they also uncover inconsistencies and biases, particularly in non-Western cultures. This work expands our understanding of LLMs’ cultural competence and emphasizes the importance of integrating diverse cultural perspectives in their development, aiming for a more globally representative and equitable approach in language modeling.
@inproceedings{mukherjee-etal-2024-global, title = {Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction Tuning}, author = {Mukherjee, Anjishnu and Caliskan, Aylin and Zhu, Ziwei and Anastasopoulos, Antonios}, editor = {Duh, Kevin and Gomez, Helena and Bethard, Steven}, booktitle = {Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)}, month = jun, year = {2024}, address = {Mexico City, Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.naacl-long.355/}, doi = {10.18653/v1/2024.naacl-long.355}, pages = {6398--6415}, } - NAACL
 Extracting Lexical Features from Dialects via Interpretable Dialect ClassifiersRoy Xie, Orevaoghene Ahia, Yulia Tsvetkov, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) code here , Jun 2024
Extracting Lexical Features from Dialects via Interpretable Dialect ClassifiersRoy Xie, Orevaoghene Ahia, Yulia Tsvetkov, and Antonios AnastasopoulosIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) code here , Jun 2024Identifying linguistic differences between dialects of a language often requires expert knowledge and meticulous human analysis. This is largely due to the complexity and nuance involved in studying various dialects. We present a novel approach to extract distinguishing lexical features of dialects by utilizing interpretable dialect classifiers, even in the absence of human experts. We explore both post-hoc and intrinsic approaches to interpretability, conduct experiments on Mandarin, Italian, and Low Saxon, and experimentally demonstrate that our method successfully identifies key language-specific lexical features that contribute to dialectal variations.
@inproceedings{xie-etal-2024-extracting, title = {Extracting Lexical Features from Dialects via Interpretable Dialect Classifiers}, author = {Xie, Roy and Ahia, Orevaoghene and Tsvetkov, Yulia and Anastasopoulos, Antonios}, editor = {Duh, Kevin and Gomez, Helena and Bethard, Steven}, booktitle = {Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers)}, month = jun, year = {2024}, address = {Mexico City, Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.naacl-short.5/}, doi = {10.18653/v1/2024.naacl-short.5}, pages = {54--69}, } - NLP4PI
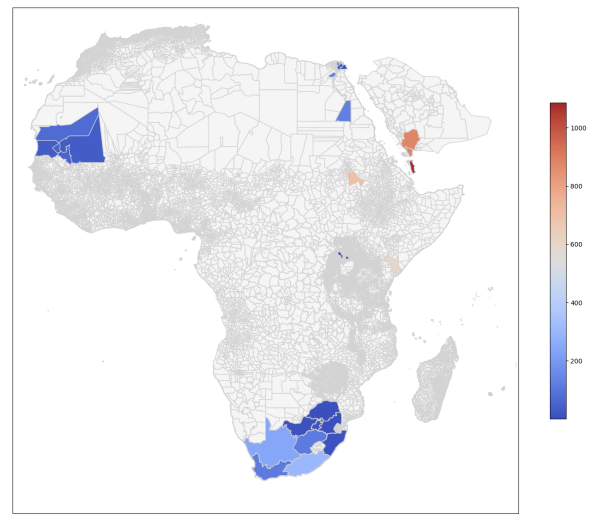 From Text to Maps: LLM-Driven Extraction and Geotagging of Epidemiological DataKarlyn K. Harrod*, Prabin Bhandari*, and Antonios AnastasopoulosIn Proceedings of the Third Workshop on NLP for Positive Impact code here , Nov 2024
From Text to Maps: LLM-Driven Extraction and Geotagging of Epidemiological DataKarlyn K. Harrod*, Prabin Bhandari*, and Antonios AnastasopoulosIn Proceedings of the Third Workshop on NLP for Positive Impact code here , Nov 2024Best Paper Award
Epidemiological datasets are essential for public health analysis and decision-making, yet they remain scarce and often difficult to compile due to inconsistent data formats, language barriers, and evolving political boundaries. Traditional methods of creating such datasets involve extensive manual effort and are prone to errors in accurate location extraction. To address these challenges, we propose utilizing large language models (LLMs) to automate the extraction and geotagging of epidemiological data from textual documents. Our approach significantly reduces the manual effort required, limiting human intervention to validating a subset of records against text snippets and verifying the geotagging reasoning, as opposed to reviewing multiple entire documents manually to extract, clean, and geotag. Additionally, the LLMs identify information often overlooked by human annotators, further enhancing the dataset‘s completeness. Our findings demonstrate that LLMs can be effectively used to semi-automate the extraction and geotagging of epidemiological data, offering several key advantages: (1) comprehensive information extraction with minimal risk of missing critical details; (2) minimal human intervention; (3) higher-resolution data with more precise geotagging; and (4) significantly reduced resource demands compared to traditional methods.
@inproceedings{harrod-etal-2024-text, title = {From Text to Maps: {LLM}-Driven Extraction and Geotagging of Epidemiological Data}, author = {Harrod, Karlyn K. and Bhandari, Prabin and Anastasopoulos, Antonios}, editor = {Dementieva, Daryna and Ignat, Oana and Jin, Zhijing and Mihalcea, Rada and Piatti, Giorgio and Tetreault, Joel and Wilson, Steven and Zhao, Jieyu}, booktitle = {Proceedings of the Third Workshop on NLP for Positive Impact}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.nlp4pi-1.24/}, doi = {10.18653/v1/2024.nlp4pi-1.24}, pages = {258--270}, } - VarDialData-Augmentation-Based Dialectal Adaptation for LLMsFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the Eleventh Workshop on NLP for Similar Languages, Varieties, and Dialects (VarDial 2024) code here , Jun 2024
This report presents gmnlp‘s participation to the Dialect-Copa shared task at VarDial 2024 (Chifu et al., 2024), which focuses on evaluating the commonsense reasoning capabilities of large language models (LLMs) on South Slavic micro-dialects. The task aims to assess how well LLMs can handle non-standard dialectal varieties, as their performance on standard languages is already well-established. We propose an approach that combines the strengths of different types of language models and leverages data augmentation techniques to improve task performance on three South Slavic dialects: Chakavian, Cherkano, and Torlak. We conduct experiments using a language-family-focused encoder-based model (BERTić) and a domain-agnostic multilingual model (AYA-101). Our results demonstrate that the proposed data augmentation techniques lead to substantial performance gains across all three test datasets in the open-source model category. This work highlights the practical utility of data augmentation and the potential of LLMs in handling non-standard dialectal varieties, contributing to the broader goal of advancing natural language understanding in low-resource and dialectal settings.
@inproceedings{faisal-anastasopoulos-2024-data, title = {Data-Augmentation-Based Dialectal Adaptation for {LLM}s}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Scherrer, Yves and Jauhiainen, Tommi and Ljube{\v{s}}i{\'c}, Nikola and Zampieri, Marcos and Nakov, Preslav and Tiedemann, J{\"o}rg}, booktitle = {Proceedings of the Eleventh Workshop on NLP for Similar Languages, Varieties, and Dialects (VarDial 2024)}, month = jun, year = {2024}, address = {Mexico City, Mexico}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.vardial-1.17/}, doi = {10.18653/v1/2024.vardial-1.17}, pages = {197--208}, } - EmoMix-3L: A Code-Mixed Dataset for Bangla-English-Hindi for Emotion DetectionNishat Raihan, Dhiman Goswami, Antara Mahmud, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the 7th Workshop on Indian Language Data: Resources and Evaluation code here , May 2024
Code-mixing is a well-studied linguistic phenomenon that occurs when two or more languages are mixed in text or speech. Several studies have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce EmoMix-3L, a novel multi-label emotion detection dataset containing code-mixed data from three different languages. We experiment with several models on EmoMix-3L and we report that MuRIL outperforms other models on this dataset.
@inproceedings{raihan-etal-2024-emomix, title = {{E}mo{M}ix-3{L}: A Code-Mixed Dataset for {B}angla-{E}nglish-{H}indi for Emotion Detection}, author = {Raihan, Nishat and Goswami, Dhiman and Mahmud, Antara and Anastasopoulos, Antonios and Zampieri, Marcos}, editor = {Jha, Girish Nath and L., Sobha and Bali, Kalika and Ojha, Atul Kr.}, booktitle = {Proceedings of the 7th Workshop on Indian Language Data: Resources and Evaluation}, month = may, year = {2024}, address = {Torino, Italia}, publisher = {ELRA and ICCL}, url = {https://aclanthology.org/2024.wildre-1.2/}, pages = {11--16}, } - WMTFindings of the WMT 2024 Shared Task of the Open Language Data InitiativeJean Maillard, Laurie Burchell, Antonios Anastasopoulos, Christian Federmann, Philipp Koehn, and Skyler WangIn Proceedings of the Ninth Conference on Machine Translation, Nov 2024
We present the results of the WMT 2024 shared task of the Open Language Data Initiative. Participants were invited to contribute to the FLORES+ and MT Seed multilingual datasets, two foundational open resources that facilitate the organic expansion of language technology‘s reach. We accepted ten submissions covering 16 languages, which extended the range of languages included in the datasets and improved the quality of existing data.
@inproceedings{maillard-etal-2024-findings, title = {Findings of the {WMT} 2024 Shared Task of the Open Language Data Initiative}, author = {Maillard, Jean and Burchell, Laurie and Anastasopoulos, Antonios and Federmann, Christian and Koehn, Philipp and Wang, Skyler}, editor = {Haddow, Barry and Kocmi, Tom and Koehn, Philipp and Monz, Christof}, booktitle = {Proceedings of the Ninth Conference on Machine Translation}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.wmt-1.4/}, doi = {10.18653/v1/2024.wmt-1.4}, pages = {110--117}, } - SIGSPATIAL
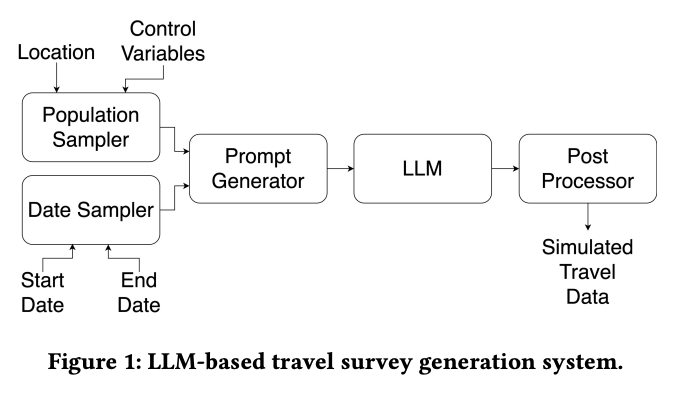 Urban Mobility Assessment Using LLMsPrabin Bhandari, Antonios Anastasopoulos, and Dieter PfoserIn Proceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems, Atlanta, GA, USA, Nov 2024
Urban Mobility Assessment Using LLMsPrabin Bhandari, Antonios Anastasopoulos, and Dieter PfoserIn Proceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems, Atlanta, GA, USA, Nov 2024Best Research Paper of the Conference
In urban science, understanding mobility patterns and analyzing how people move around cities helps improve the overall quality of life and supports the development of more livable, efficient, and sustainable urban areas. A challenging aspect of this work is the collection of mobility data through user tracking or travel surveys, given the associated privacy concerns, noncompliance, and high cost. This work proposes an innovative AI-based approach for synthesizing travel surveys by prompting large language models (LLMs), aiming to leverage their vast amount of relevant background knowledge and text generation capabilities. Our study evaluates the effectiveness of this approach across various U.S. metropolitan areas by comparing the results against existing survey data at different granularity levels. These levels include (i) pattern level, which compares aggregated metrics such as the average number of locations traveled and travel time, (ii) trip level, which focuses on comparing trips as whole units using transition probabilities, and (iii) activity chain level, which examines the sequence of locations visited by individuals. Our work covers several proprietary and open-source LLMs, revealing that open-source base models like Llama-2, when fine-tuned on even a limited amount of actual data, can generate synthetic data that closely mimics the actual travel survey data and, as such, provides an argument for using such data in mobility studies.
@inproceedings{bhandari-etal-24-urban, author = {Bhandari, Prabin and Anastasopoulos, Antonios and Pfoser, Dieter}, title = {Urban Mobility Assessment Using LLMs}, year = {2024}, month = nov, isbn = {9798400711077}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3678717.3691221}, doi = {10.1145/3678717.3691221}, booktitle = {Proceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems}, pages = {67–79}, numpages = {13}, keywords = {Large Language Models, Travel Data, Travel Survey, Travel Survey Data Simulation}, location = {Atlanta, GA, USA}, series = {SIGSPATIAL '24}, } - SIGSPATIAL Trajectory Anomaly Detection with Language ModelsJonathan Kabala Mbuya, Dieter Pfoser, and Antonios AnastasopoulosIn Proceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems, Atlanta, GA, USA, Nov 2024
This paper presents a novel approach for trajectory anomaly detection using an autoregressive causal-attention model, termed LM-TAD. This method leverages the similarities between language statements and trajectories, both of which consist of ordered elements requiring coherence through external rules and contextual variations. By treating trajectories as sequences of tokens, our model learns the probability distributions over trajectories, enabling the identification of anomalous locations with high precision. We incorporate user-specific tokens to account for individual behavior patterns, enhancing anomaly detection tailored to user context. Our experiments demonstrate the effectiveness of LM-TAD on both synthetic and real-world datasets. In particular, the model outperforms existing methods on the Pattern of Life (PoL) dataset by detecting user-contextual anomalies and achieves competitive results on the Porto taxi dataset, highlighting its adaptability and robustness. Additionally, we introduce the use of perplexity and surprisal rate metrics for detecting outliers and pinpointing specific anomalous locations within trajectories. The LM-TAD framework supports various trajectory representations, including GPS coordinates, staypoints, and activity types, proving its versatility in handling diverse trajectory data. Moreover, our approach is well-suited for online trajectory anomaly detection, significantly reducing computational latency by caching key-value states of the attention mechanism, thereby avoiding repeated computations. The code to reproduce experiments in this paper can be found at the following link: https://github.com/jonathankabala/LMTAD.
@inproceedings{10.1145/3678717.3691257, author = {Mbuya, Jonathan Kabala and Pfoser, Dieter and Anastasopoulos, Antonios}, title = {Trajectory Anomaly Detection with Language Models}, year = {2024}, month = nov, isbn = {9798400711077}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3678717.3691257}, doi = {10.1145/3678717.3691257}, booktitle = {Proceedings of the 32nd ACM International Conference on Advances in Geographic Information Systems}, pages = {208–219}, numpages = {12}, keywords = {Anomalous Trajectories, Anomaly Detection, Language Modeling, Self-Supervised Learning, Trajectory Data}, location = {Atlanta, GA, USA}, series = {SIGSPATIAL '24}, } - JAMIAClinical risk prediction using language models: benefits and considerationsAngeela Acharya, Sulabh Shrestha, Anyi Chen, Joseph Conte, Sanja Avramovic, Siddhartha Sikdar, Antonios Anastasopoulos, and Sanmay DasJournal of the American Medical Informatics Association, Feb 2024
The use of electronic health records (EHRs) for clinical risk prediction is on the rise. However, in many practical settings, the limited availability of task-specific EHR data can restrict the application of standard machine learning pipelines. In this study, we investigate the potential of leveraging language models (LMs) as a means to incorporate supplementary domain knowledge for improving the performance of various EHR-based risk prediction tasks.We propose two novel LM-based methods, namely “LLaMA2-EHR” and “Sent-e-Med.” Our focus is on utilizing the textual descriptions within structured EHRs to make risk predictions about future diagnoses. We conduct a comprehensive comparison with previous approaches across various data types and sizes.Experiments across 6 different methods and 3 separate risk prediction tasks reveal that employing LMs to represent structured EHRs, such as diagnostic histories, results in significant performance improvements when evaluated using standard metrics such as area under the receiver operating characteristic (ROC) curve and precision-recall (PR) curve. Additionally, they offer benefits such as few-shot learning, the ability to handle previously unseen medical concepts, and adaptability to various medical vocabularies. However, it is noteworthy that outcomes may exhibit sensitivity to a specific prompt.LMs encompass extensive embedded knowledge, making them valuable for the analysis of EHRs in the context of risk prediction. Nevertheless, it is important to exercise caution in their application, as ongoing safety concerns related to LMs persist and require continuous consideration.
@article{10.1093/jamia/ocae030, author = {Acharya, Angeela and Shrestha, Sulabh and Chen, Anyi and Conte, Joseph and Avramovic, Sanja and Sikdar, Siddhartha and Anastasopoulos, Antonios and Das, Sanmay}, title = {Clinical risk prediction using language models: benefits and considerations}, journal = {Journal of the American Medical Informatics Association}, volume = {31}, number = {9}, pages = {1856-1864}, year = {2024}, month = feb, issn = {1527-974X}, doi = {10.1093/jamia/ocae030}, url = {https://doi.org/10.1093/jamia/ocae030}, eprint = {https://academic.oup.com/jamia/article-pdf/31/9/1856/58868302/ocae030.pdf}, } - AIES
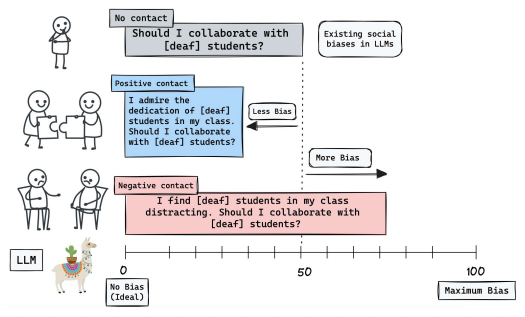 Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact HypothesisChahat Raj, Anjishnu Mukherjee, Aylin Caliskan, Antonios Anastasopoulos, and Ziwei ZhuProceedings of the AAAI/ACM Conference on AI, Ethics, and Society Code here , Oct 2024
Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact HypothesisChahat Raj, Anjishnu Mukherjee, Aylin Caliskan, Antonios Anastasopoulos, and Ziwei ZhuProceedings of the AAAI/ACM Conference on AI, Ethics, and Society Code here , Oct 2024Large Language Models (LLMs) perpetuate social biases, reflecting prejudices in their training data and reinforcing societal stereotypes and inequalities. Our work explores the potential of the Contact Hypothesis, a concept from social psychology for debiasing LLMs. We simulate various forms of social contact through LLM prompting to measure their influence on the model’s biases, mirroring how intergroup interactions can reduce prejudices in social contexts. We create a dataset of 108,000 prompts following a principled approach replicating social contact to measure biases in three LLMs (LLaMA 2, Tulu, and NousHermes) across 13 social bias dimensions. We propose a unique debiasing technique, Social Contact Debiasing (SCD), that instruction-tunes these models with unbiased responses to prompts. Our research demonstrates that LLM responses exhibit social biases when subject to contact probing, but more importantly, these biases can be significantly reduced by up to 40% in 1 epoch of instruction tuning LLaMA 2 following our SCD strategy.
@article{Raj_Mukherjee_Caliskan_Anastasopoulos_Zhu_2024, title = {Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis}, volume = {7}, url = {https://ojs.aaai.org/index.php/AIES/article/view/31715}, doi = {10.1609/aies.v7i1.31715}, number = {1}, journal = {Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society}, author = {Raj, Chahat and Mukherjee, Anjishnu and Caliskan, Aylin and Anastasopoulos, Antonios and Zhu, Ziwei}, year = {2024}, month = oct, pages = {1180-1189}, } - ECIR
 SALSA: Salience-Based Switching Attack for Adversarial Perturbations in Fake News Detection ModelsChahat Raj*, Anjishnu Mukherjee*, Hemant Purohit, Antonios Anastasopoulos, and Ziwei ZhuIn European Conference on Information Retrieval Code here , Oct 2024
SALSA: Salience-Based Switching Attack for Adversarial Perturbations in Fake News Detection ModelsChahat Raj*, Anjishnu Mukherjee*, Hemant Purohit, Antonios Anastasopoulos, and Ziwei ZhuIn European Conference on Information Retrieval Code here , Oct 2024@inproceedings{raj2024salsa, title = {SALSA: Salience-Based Switching Attack for Adversarial Perturbations in Fake News Detection Models}, author = {Raj, Chahat and Mukherjee, Anjishnu and Purohit, Hemant and Anastasopoulos, Antonios and Zhu, Ziwei}, booktitle = {European Conference on Information Retrieval}, pages = {35--49}, year = {2024}, organization = {Springer}, } - InterspeechSpeech Recognition for Greek Dialects: A Challenging BenchmarkSocrates Vakirtzian, Chara Tsoukala, Stavros Bompolas, Katerina Mouzou, Vivian Stamou, Georgios Paraskevopoulos, Antonios Dimakis, Stella Markantonatou, Angela Ralli, and Antonios AnastasopoulosIn Interspeech 2024, Oct 2024
Language technologies should be judged on their usefulness in real-world use cases. Despite recent impressive progress in automatic speech recognition (ASR), an often overlooked aspect in ASR research and evaluation is language variation in the form of non-standard dialects or language varieties. To this end, this work introduces a challenging benchmark that focuses on four varieties of Greek (Aivaliot, Cretan, Griko, Messenian) encompassing challenges related to data availability, orthographic conventions, and complexities arising from language contact. Initial experiments with state-of-the-art models and established cross-lingual transfer techniques highlight the difficulty of adapting to such low-resource varieties.
@inproceedings{vakirtzian24_interspeech, title = {Speech Recognition for Greek Dialects: A Challenging Benchmark}, author = {Vakirtzian, Socrates and Tsoukala, Chara and Bompolas, Stavros and Mouzou, Katerina and Stamou, Vivian and Paraskevopoulos, Georgios and Dimakis, Antonios and Markantonatou, Stella and Ralli, Angela and Anastasopoulos, Antonios}, year = {2024}, booktitle = {Interspeech 2024}, pages = {3974--3978}, doi = {10.21437/Interspeech.2024-2443}, issn = {2958-1796}, }



















2023
- SIGSPATIAL
 Are Large Language Models Geospatially Knowledgeable?Prabin Bhandari, Antonios Anastasopoulos, and Dieter PfoserIn Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, Hamburg, Germany, Oct 2023
Are Large Language Models Geospatially Knowledgeable?Prabin Bhandari, Antonios Anastasopoulos, and Dieter PfoserIn Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems, Hamburg, Germany, Oct 2023Despite the impressive performance of Large Language Models (LLM) for various natural language processing tasks, little is known about their comprehension of geographic data and related ability to facilitate informed geospatial decision-making. This paper investigates the extent of geospatial knowledge, awareness, and reasoning abilities encoded within such pretrained LLMs. With a focus on autoregressive language models, we devise experimental approaches related to (i) probing LLMs for geo-coordinates to assess geospatial knowledge, (ii) using geospatial and non-geospatial prepositions to gauge their geospatial awareness, and (iii) utilizing a multidimensional scaling (MDS) experiment to assess the models’ geospatial reasoning capabilities and to determine locations of cities based on prompting. Our results confirm that it does not only take larger but also more sophisticated LLMs to synthesize geospatial knowledge from textual information. As such, this research contributes to understanding the potential and limitations of LLMs in dealing with geospatial information.
@inproceedings{bhandari-etal-23-geospatially, author = {Bhandari, Prabin and Anastasopoulos, Antonios and Pfoser, Dieter}, title = {Are Large Language Models Geospatially Knowledgeable?}, year = {2023}, month = oct, isbn = {9798400701689}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3589132.3625625}, doi = {10.1145/3589132.3625625}, booktitle = {Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems}, articleno = {75}, numpages = {4}, keywords = {geospatial reasoning, geospatial awareness, geospatial knowledge, large language models}, location = {Hamburg, Germany}, series = {SIGSPATIAL '23}, } - INLGTrustworthiness of Children Stories Generated by Large Language ModelsPrabin Bhandari, and Hannah BrennanIn Proceedings of the 16th International Natural Language Generation Conference Code here , Sep 2023
Large Language Models (LLMs) have shown a tremendous capacity for generating literary text. However, their effectiveness in generating children‘s stories has yet to be thoroughly examined. In this study, we evaluate the trustworthiness of children‘s stories generated by LLMs using various measures, and we compare and contrast our results with both old and new children‘s stories to better assess their significance. Our findings suggest that LLMs still struggle to generate children‘s stories at the level of quality and nuance found in actual stories.
@inproceedings{bhandari-brennan-2023-trustworthiness, title = {Trustworthiness of Children Stories Generated by Large Language Models}, author = {Bhandari, Prabin and Brennan, Hannah}, editor = {Keet, C. Maria and Lee, Hung-Yi and Zarrie{\ss}, Sina}, booktitle = {Proceedings of the 16th International Natural Language Generation Conference}, month = sep, year = {2023}, address = {Prague, Czechia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.inlg-main.24/}, doi = {10.18653/v1/2023.inlg-main.24}, pages = {352--361} } - MRL
 Geographic and Geopolitical Biases of Language ModelsFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL) Code here , Dec 2023
Geographic and Geopolitical Biases of Language ModelsFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL) Code here , Dec 2023@inproceedings{faisal-anastasopoulos-2023-geographic, title = {Geographic and Geopolitical Biases of Language Models}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Ataman, Duygu}, booktitle = {Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL)}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.mrl-1.12/}, doi = {10.18653/v1/2023.mrl-1.12}, pages = {139--163}, } - ACL
 BIG-C: a Multimodal Multi-Purpose Dataset for BembaClaytone Sikasote, Eunice Mukonde, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , Jul 2023
BIG-C: a Multimodal Multi-Purpose Dataset for BembaClaytone Sikasote, Eunice Mukonde, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , Jul 2023We present BIG-C (Bemba Image Grounded Conversations), a large multimodal dataset for Bemba. While Bemba is the most populous language of Zambia, it exhibits a dearth of resources which render the development of language technologies or language processing research almost impossible. The dataset is comprised of multi-turn dialogues between Bemba speakers based on images, transcribed and translated into English. There are more than 92,000 utterances/sentences, amounting to more than 180 hours of audio data with corresponding transcriptions and English translations. We also provide baselines on speech recognition (ASR), machine translation (MT) and speech translation (ST) tasks, and sketch out other potential future multimodal uses of our dataset. We hope that by making the dataset available to the research community, this work will foster research and encourage collaboration across the language, speech, and vision communities especially for languages outside the “traditionally” used high-resourced ones. All data and code are publicly available: [\urlhttps://github.com/csikasote/bigc](\urlhttps://github.com/csikasote/bigc).
@inproceedings{sikasote-etal-2023-big, title = {{BIG}-{C}: a Multimodal Multi-Purpose Dataset for {B}emba}, author = {Sikasote, Claytone and Mukonde, Eunice and Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Rogers, Anna and Boyd-Graber, Jordan and Okazaki, Naoaki}, booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-long.115/}, doi = {10.18653/v1/2023.acl-long.115}, pages = {2062--2078}, } - ACL
 Script Normalization for Unconventional Writing of Under-Resourced Languages in Bilingual CommunitiesSina Ahmadi, and Antonios AnastasopoulosIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , Jul 2023
Script Normalization for Unconventional Writing of Under-Resourced Languages in Bilingual CommunitiesSina Ahmadi, and Antonios AnastasopoulosIn Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , Jul 2023The wide accessibility of social media has provided linguistically under-represented communities with an extraordinary opportunity to create content in their native languages. This, however, comes with certain challenges in script normalization, particularly where the speakers of a language in a bilingual community rely on another script or orthography to write their native language. This paper addresses the problem of script normalization for several such languages that are mainly written in a Perso-Arabic script. Using synthetic data with various levels of noise and a transformer-based model, we demonstrate that the problem can be effectively remediated. We conduct a small-scale evaluation of real data as well. Our experiments indicate that script normalization is also beneficial to improve the performance of downstream tasks such as machine translation and language identification.
@inproceedings{ahmadi-anastasopoulos-2023-script, title = {Script Normalization for Unconventional Writing of Under-Resourced Languages in Bilingual Communities}, author = {Ahmadi, Sina and Anastasopoulos, Antonios}, editor = {Rogers, Anna and Boyd-Graber, Jordan and Okazaki, Naoaki}, booktitle = {Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.acl-long.809/}, doi = {10.18653/v1/2023.acl-long.809}, pages = {14466--14487}, } - BLP-2023Offensive Language Identification in Transliterated and Code-Mixed BanglaMd Nishat Raihan, Umma Tanmoy, Anika Binte Islam, Kai North, Tharindu Ranasinghe, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the First Workshop on Bangla Language Processing (BLP-2023) Code here , Dec 2023
Identifying offensive content in social media is vital to create safe online communities. Several recent studies have addressed this problem by creating datasets for various languages. In this paper, we explore offensive language identification in texts with transliterations and code-mixing, linguistic phenomena common in multilingual societies, and a known challenge for NLP systems. We introduce TB-OLID, a transliterated Bangla offensive language dataset containing 5,000 manually annotated comments. We train and fine-tune machine learning models on TB-OLID, and we evaluate their results on this dataset. Our results show that English pre-trained transformer-based models, such as fBERT and HateBERT achieve the best performance on this dataset.
@inproceedings{raihan-etal-2023-offensive, title = {Offensive Language Identification in Transliterated and Code-Mixed {B}angla}, author = {Raihan, Md Nishat and Tanmoy, Umma and Islam, Anika Binte and North, Kai and Ranasinghe, Tharindu and Anastasopoulos, Antonios and Zampieri, Marcos}, editor = {Alam, Firoj and Kar, Sudipta and Chowdhury, Shammur Absar and Sadeque, Farig and Amin, Ruhul}, booktitle = {Proceedings of the First Workshop on Bangla Language Processing (BLP-2023)}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.banglalp-1.1/}, doi = {10.18653/v1/2023.banglalp-1.1}, pages = {1--6}, } - ComputEL
 User-Centric Evaluation of OCR Systems for Kwak‘walaShruti Rijhwani, Daisy Rosenblum, Michayla King, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the Sixth Workshop on the Use of Computational Methods in the Study of Endangered Languages Code here , Mar 2023
User-Centric Evaluation of OCR Systems for Kwak‘walaShruti Rijhwani, Daisy Rosenblum, Michayla King, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the Sixth Workshop on the Use of Computational Methods in the Study of Endangered Languages Code here , Mar 2023@inproceedings{rijhwani-etal-2023-user, title = {User-Centric Evaluation of {OCR} Systems for Kwak`wala}, author = {Rijhwani, Shruti and Rosenblum, Daisy and King, Michayla and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Harrigan, Atticus and Chaudhary, Aditi and Rijhwani, Shruti and Moeller, Sarah and Arppe, Antti and Palmer, Alexis and Henke, Ryan and Rosenblum, Daisy}, booktitle = {Proceedings of the Sixth Workshop on the Use of Computational Methods in the Study of Endangered Languages}, month = mar, year = {2023}, address = {Remote}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.computel-1.4/}, pages = {19--29}, } - EACL
 Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable SurveySachin Kumar, Vidhisha Balachandran, Lucille Njoo, Antonios Anastasopoulos, and Yulia TsvetkovIn Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, May 2023
Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable SurveySachin Kumar, Vidhisha Balachandran, Lucille Njoo, Antonios Anastasopoulos, and Yulia TsvetkovIn Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, May 2023Recent advances in the capacity of large language models to generate human-like text have resulted in their increased adoption in user-facing settings. In parallel, these improvements have prompted a heated discourse around the risks of societal harms they introduce, whether inadvertent or malicious. Several studies have explored these harms and called for their mitigation via development of safer, fairer models. Going beyond enumerating the risks of harms, this work provides a survey of practical methods for addressing potential threats and societal harms from language generation models. We draw on several prior works’ taxonomies of language model risks to present a structured overview of strategies for detecting and ameliorating different kinds of risks/harms of language generators. Bridging diverse strands of research, this survey aims to serve as a practical guide for both LM researchers and practitioners, with explanations of different strategies’ motivations, their limitations, and open problems for future research.
@inproceedings{kumar-etal-2023-language, title = {Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey}, author = {Kumar, Sachin and Balachandran, Vidhisha and Njoo, Lucille and Anastasopoulos, Antonios and Tsvetkov, Yulia}, editor = {Vlachos, Andreas and Augenstein, Isabelle}, booktitle = {Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics}, month = may, year = {2023}, address = {Dubrovnik, Croatia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.eacl-main.241/}, doi = {10.18653/v1/2023.eacl-main.241}, pages = {3299--3321}, } - EMNLP
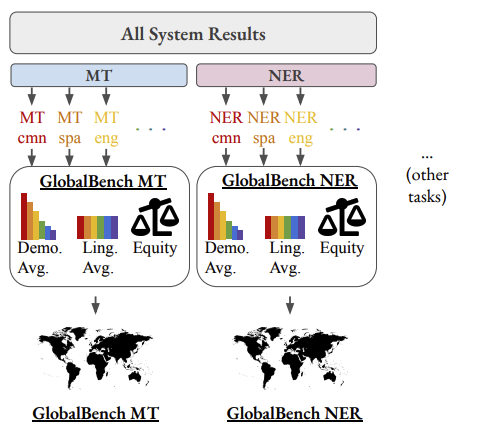 GlobalBench: A Benchmark for Global Progress in Natural Language ProcessingYueqi Song, Simran Khanuja, Pengfei Liu, Fahim Faisal, Alissa Ostapenko, Genta Winata, Alham Fikri Aji, Samuel Cahyawijaya, Yulia Tsvetkov, Antonios Anastasopoulos, and 1 more authorIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023
GlobalBench: A Benchmark for Global Progress in Natural Language ProcessingYueqi Song, Simran Khanuja, Pengfei Liu, Fahim Faisal, Alissa Ostapenko, Genta Winata, Alham Fikri Aji, Samuel Cahyawijaya, Yulia Tsvetkov, Antonios Anastasopoulos, and 1 more authorIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023Despite the major advances in NLP, significant disparities in NLP system performance across languages still exist. Arguably, these are due to uneven resource allocation and sub-optimal incentives to work on less resourced languages. To track and further incentivize the global development of equitable language technology, we introduce GlobalBench. Prior multilingual benchmarks are static and have focused on a limited number of tasks and languages. In contrast, GlobalBench is an ever-expanding collection that aims to dynamically track progress on all NLP datasets in all languages. Rather than solely measuring accuracy, GlobalBench also tracks the estimated per-speaker utility and equity of technology across all languages, providing a multi-faceted view of how language technology is serving people of the world. Furthermore, GlobalBench is designed to identify the most under-served languages, and rewards research efforts directed towards those languages. At present, the most under-served languages are the ones with a relatively high population, but nonetheless overlooked by composite multilingual benchmarks (like Punjabi, Portuguese, and Wu Chinese). Currently, GlobalBench covers 966 datasets in 190 languages, and has 1,128 system submissions spanning 62 languages.
@inproceedings{song-etal-2023-globalbench, title = {{G}lobal{B}ench: A Benchmark for Global Progress in Natural Language Processing}, author = {Song, Yueqi and Khanuja, Simran and Liu, Pengfei and Faisal, Fahim and Ostapenko, Alissa and Winata, Genta and Aji, Alham Fikri and Cahyawijaya, Samuel and Tsvetkov, Yulia and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.emnlp-main.875/}, doi = {10.18653/v1/2023.emnlp-main.875}, pages = {14157--14171}, } - EMNLP
 LIMIT: Language Identification, Misidentification, and Translation using Hierarchical Models in 350+ LanguagesMilind Agarwal, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023
LIMIT: Language Identification, Misidentification, and Translation using Hierarchical Models in 350+ LanguagesMilind Agarwal, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023Knowing the language of an input text/audio is a necessary first step for using almost every NLP tool such as taggers, parsers, or translation systems. Language identification is a well-studied problem, sometimes even considered solved; in reality, due to lack of data and computational challenges, current systems cannot accurately identify most of the world‘s 7000 languages. To tackle this bottleneck, we first compile a corpus, MCS-350, of 50K multilingual and parallel children‘s stories in 350+ languages. MCS-350 can serve as a benchmark for language identification of short texts and for 1400+ new translation directions in low-resource Indian and African languages. Second, we propose a novel misprediction-resolution hierarchical model, LIMIT, for language identification that reduces error by 55% (from 0.71 to 0.32) on our compiled children‘s stories dataset and by 40% (from 0.23 to 0.14) on the FLORES-200 benchmark. Our method can expand language identification coverage into low-resource languages by relying solely on systemic misprediction patterns, bypassing the need to retrain large models from scratch.
@inproceedings{agarwal-etal-2023-limit, title = {{LIMIT}: Language Identification, Misidentification, and Translation using Hierarchical Models in 350+ Languages}, author = {Agarwal, Milind and Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.emnlp-main.895/}, doi = {10.18653/v1/2023.emnlp-main.895}, pages = {14496--14519}, } - EMNLP
 Global Voices, Local Biases: Socio-Cultural Prejudices across LanguagesAnjishnu Mukherjee*, Chahat Raj*, Ziwei Zhu, and Antonios AnastasopoulosIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023
Global Voices, Local Biases: Socio-Cultural Prejudices across LanguagesAnjishnu Mukherjee*, Chahat Raj*, Ziwei Zhu, and Antonios AnastasopoulosIn Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing Code here , Dec 2023Human biases are ubiquitous but not uniform: disparities exist across linguistic, cultural, and societal borders. As large amounts of recent literature suggest, language models (LMs) trained on human data can reflect and often amplify the effects of these social biases. However, the vast majority of existing studies on bias are heavily skewed towards Western and European languages. In this work, we scale the Word Embedding Association Test (WEAT) to 24 languages, enabling broader studies and yielding interesting findings about LM bias. We additionally enhance this data with culturally relevant information for each language, capturing local contexts on a global scale. Further, to encompass more widely prevalent societal biases, we examine new bias dimensions across toxicity, ableism, and more. Moreover, we delve deeper into the Indian linguistic landscape, conducting a comprehensive regional bias analysis across six prevalent Indian languages. Finally, we highlight the significance of these social biases and the new dimensions through an extensive comparison of embedding methods, reinforcing the need to address them in pursuit of more equitable language models.
@inproceedings{mukherjee-etal-2023-global, title = {{G}lobal {V}oices, Local Biases: Socio-Cultural Prejudices across Languages}, author = {Mukherjee, Anjishnu and Raj, Chahat and Zhu, Ziwei and Anastasopoulos, Antonios}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.emnlp-main.981/}, doi = {10.18653/v1/2023.emnlp-main.981}, pages = {15828--15845}, } - FieldMattersApproaches to Corpus Creation for Low-Resource Language Technology: the Case of Southern Kurdish and LakiSina Ahmadi, Zahra Azin, Sara Belelli, and Antonios AnastasopoulosIn Proceedings of the Second Workshop on NLP Applications to Field Linguistics Code here , May 2023
One of the major challenges that under-represented and endangered language communities face in language technology is the lack or paucity of language data. This is also the case of the Southern varieties of the Kurdish and Laki languages for which very limited resources are available with insubstantial progress in tools. To tackle this, we provide a few approaches that rely on the content of local news websites, a local radio station that broadcasts content in Southern Kurdish and fieldwork for Laki. In this paper, we describe some of the challenges of such under-represented languages, particularly in writing and standardization, and also, in retrieving sources of data and retro-digitizing handwritten content to create a corpus for Southern Kurdish and Laki. In addition, we study the task of language identification in light of the other variants of Kurdish and Zaza-Gorani languages.
@inproceedings{ahmadi-etal-2023-approaches, title = {Approaches to Corpus Creation for Low-Resource Language Technology: the Case of {S}outhern {K}urdish and {L}aki}, author = {Ahmadi, Sina and Azin, Zahra and Belelli, Sara and Anastasopoulos, Antonios}, editor = {Serikov, Oleg and Voloshina, Ekaterina and Postnikova, Anna and Klyachko, Elena and Vylomova, Ekaterina and Shavrina, Tatiana and Le Ferrand, Eric and Malykh, Valentin and Tyers, Francis and Arkhangelskiy, Timofey and Mikhailov, Vladislav}, booktitle = {Proceedings of the Second Workshop on NLP Applications to Field Linguistics}, month = may, year = {2023}, address = {Dubrovnik, Croatia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.fieldmatters-1.7/}, doi = {10.18653/v1/2023.fieldmatters-1.7}, pages = {52--63}, } - EACL
 Noisy Parallel Data AlignmentRuoyu Xie, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EACL 2023 Code here , May 2023
Noisy Parallel Data AlignmentRuoyu Xie, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EACL 2023 Code here , May 2023An ongoing challenge in current natural language processing is how its major advancements tend to disproportionately favor resource-rich languages, leaving a significant number of under-resourced languages behind. Due to the lack of resources required to train and evaluate models, most modern language technologies are either nonexistent or unreliable to process endangered, local, and non-standardized languages. Optical character recognition (OCR) is often used to convert endangered language documents into machine-readable data. However, such OCR output is typically noisy, and most word alignment models are not built to work under such noisy conditions. In this work, we study the existing word-level alignment models under noisy settings and aim to make them more robust to noisy data. Our noise simulation and structural biasing method, tested on multiple language pairs, manages to reduce the alignment error rate on a state-of-the-art neural-based alignment model up to 59.6%.
@inproceedings{xie-anastasopoulos-2023-noisy, title = {Noisy Parallel Data Alignment}, author = {Xie, Ruoyu and Anastasopoulos, Antonios}, editor = {Vlachos, Andreas and Augenstein, Isabelle}, booktitle = {Findings of the Association for Computational Linguistics: EACL 2023}, month = may, year = {2023}, address = {Dubrovnik, Croatia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.findings-eacl.111/}, doi = {10.18653/v1/2023.findings-eacl.111}, pages = {1501--1513}, } - EMNLP
 Teacher Perception of Automatically Extracted Grammar Concepts for L2 Language LearningAditi Chaudhary, Arun Sampath, Ashwin Sheshadri, Antonios Anastasopoulos, and Graham NeubigIn Findings of the Association for Computational Linguistics: EMNLP 2023, Dec 2023
Teacher Perception of Automatically Extracted Grammar Concepts for L2 Language LearningAditi Chaudhary, Arun Sampath, Ashwin Sheshadri, Antonios Anastasopoulos, and Graham NeubigIn Findings of the Association for Computational Linguistics: EMNLP 2023, Dec 2023One of the challenges in language teaching is how best to organize rules regarding syntax, semantics, or phonology in a meaningful manner. This not only requires content creators to have pedagogical skills, but also have that language‘s deep understanding. While comprehensive materials to develop such curricula are available in English and some broadly spoken languages, for many other languages, teachers need to manually create them in response to their students’ needs. This is challenging because i) it requires that such experts be accessible and have the necessary resources, and ii) describing all the intricacies of a language is time-consuming and prone to omission. In this work, we aim to facilitate this process by automatically discovering and visualizing grammar descriptions. We extract descriptions from a natural text corpus that answer questions about morphosyntax (learning of word order, agreement, case marking, or word formation) and semantics (learning of vocabulary). We apply this method for teaching two Indian languages, Kannada and Marathi, which, unlike English, do not have well-developed resources for second language learning. To assess the perceived utility of the extracted material, we enlist the help of language educators from schools in North America to perform a manual evaluation, who find the materials have potential to be used for their lesson preparation and learner evaluation.
@inproceedings{chaudhary-etal-2023-teacher, title = {Teacher Perception of Automatically Extracted Grammar Concepts for {L}2 Language Learning}, author = {Chaudhary, Aditi and Sampath, Arun and Sheshadri, Ashwin and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Bouamor, Houda and Pino, Juan and Bali, Kalika}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2023}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.findings-emnlp.246/}, doi = {10.18653/v1/2023.findings-emnlp.246}, pages = {3776--3793}, } - IWSLTGMU Systems for the IWSLT 2023 Dialect and Low-resource Speech Translation TasksJonathan Mbuya, and Antonios AnastasopoulosIn Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023), Jul 2023
This paper describes the GMU Systems for the IWSLT 2023 Dialect and Low-resource Speech Translation Tasks. We submitted systems for five low-resource tasks and the dialectal task. In this work, we explored self-supervised pre-trained speech models and finetuned them on speech translation downstream tasks. We use the Wav2vec 2.0, XLSR-53, and Hubert as self-supervised models. Unlike Hubert, Wav2vec 2.0 and XLSR-53 achieve the best results when we remove the top three layers. Our results show that Wav2vec 2.0 and Hubert perform similarly with their relative best configuration. In addition, we found that Wav2vec 2.0 pre-trained on audio data of the same language as the source language of a speech translation model achieves better results. For the low-resource setting, the best results are achieved using either the Wav2vec 2.0 or Hubert models, while XLSR-53 achieves the best results for the dialectal transfer task. We find that XLSR-53 does not perform well for low-resource tasks. Using Wav2vec 2.0, we report close to 2 BLEU point improvements on the test set for the Tamasheq-French compared to the baseline system at the IWSLT 2022.
@inproceedings{mbuya-anastasopoulos-2023-gmu, title = {{GMU} Systems for the {IWSLT} 2023 Dialect and Low-resource Speech Translation Tasks}, author = {Mbuya, Jonathan and Anastasopoulos, Antonios}, editor = {Salesky, Elizabeth and Federico, Marcello and Carpuat, Marine}, booktitle = {Proceedings of the 20th International Conference on Spoken Language Translation (IWSLT 2023)}, month = jul, year = {2023}, address = {Toronto, Canada (in-person and online)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.iwslt-1.24/}, doi = {10.18653/v1/2023.iwslt-1.24}, pages = {269--276}, } - MRLTo token or not to token: A Comparative Study of Text Representations for Cross-Lingual TransferMd Mushfiqur Rahman, Fardin Ahsan Sakib, Fahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL) Code here , Dec 2023
@inproceedings{rahman-etal-2023-token, title = {To token or not to token: A Comparative Study of Text Representations for Cross-Lingual Transfer}, author = {Rahman, Md Mushfiqur and Sakib, Fardin Ahsan and Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Ataman, Duygu}, booktitle = {Proceedings of the 3rd Workshop on Multi-lingual Representation Learning (MRL)}, month = dec, year = {2023}, address = {Singapore}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.mrl-1.6/}, doi = {10.18653/v1/2023.mrl-1.6}, pages = {67--84}, } - SEA-LPSentMix-3L: A Novel Code-Mixed Test Dataset in Bangla-English-Hindi for Sentiment AnalysisMd Nishat Raihan*, Dhiman Goswami*, Antara Mahmud, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the First Workshop in South East Asian Language Processing Code here , Nov 2023
@inproceedings{raihan-etal-2023-sentmix, title = {{S}ent{M}ix-3{L}: A Novel Code-Mixed Test Dataset in {B}angla-{E}nglish-{H}indi for Sentiment Analysis}, author = {Raihan, Md Nishat and Goswami, Dhiman and Mahmud, Antara and Anastasopoulos, Antonios and Zampieri, Marcos}, editor = {Wijaya, Derry and Aji, Alham Fikri and Vania, Clara and Winata, Genta Indra and Purwarianti, Ayu}, booktitle = {Proceedings of the First Workshop in South East Asian Language Processing}, month = nov, year = {2023}, address = {Nusa Dua, Bali, Indonesia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.sealp-1.6/}, doi = {10.18653/v1/2023.sealp-1.6}, pages = {79--84}, } - SemEvalGMNLP at SemEval-2023 Task 12: Sentiment Analysis with Phylogeny-Based AdaptersMd Mahfuz Ibn Alam*, Ruoyu Xie*, Fahim Faisal*, and Antonios AnastasopoulosIn Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), Jul 2023
This report describes GMU‘s sentiment analysis system for the SemEval-2023 shared task AfriSenti-SemEval. We participated in all three sub-tasks: Monolingual, Multilingual, and Zero-Shot. Our approach uses models initialized with AfroXLMR-large, a pre-trained multilingual language model trained on African languages and fine-tuned correspondingly. We also introduce augmented training data along with original training data. Alongside finetuning, we perform phylogeny-based adapter-tuning to create several models and ensemble the best models for the final submission. Our system achieves the best F1-score on track 5: Amharic, with 6.2 points higher F1-score than the second-best performing system on this track. Overall, our system ranks 5th among the 10 systems participating in all 15 tracks.
@inproceedings{alam-etal-2023-gmnlp, title = {{GMNLP} at {S}em{E}val-2023 Task 12: Sentiment Analysis with Phylogeny-Based Adapters}, author = {Alam, Md Mahfuz Ibn and Xie, Ruoyu and Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Ojha, Atul Kr. and Do{\u{g}}ru{\"o}z, A. Seza and Da San Martino, Giovanni and Tayyar Madabushi, Harish and Kumar, Ritesh and Sartori, Elisa}, booktitle = {Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023)}, month = jul, year = {2023}, address = {Toronto, Canada}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.semeval-1.163/}, doi = {10.18653/v1/2023.semeval-1.163}, pages = {1172--1182}, } - SocialNLPOffMix-3L: A Novel Code-Mixed Test Dataset in Bangla-English-Hindi for Offensive Language IdentificationDhiman Goswami*, Md Nishat Raihan*, Antara Mahmud, Antonios Anastasopoulos, and Marcos ZampieriIn Proceedings of the 11th International Workshop on Natural Language Processing for Social Media Code here , Nov 2023
@inproceedings{goswami-etal-2023-offmix, title = {{O}ff{M}ix-3{L}: A Novel Code-Mixed Test Dataset in {B}angla-{E}nglish-{H}indi for Offensive Language Identification}, author = {Goswami, Dhiman and Raihan, Md Nishat and Mahmud, Antara and Anastasopoulos, Antonios and Zampieri, Marcos}, editor = {Ku, Lun-Wei and Li, Cheng-Te}, booktitle = {Proceedings of the 11th International Workshop on Natural Language Processing for Social Media}, month = nov, year = {2023}, address = {Bali, Indonesia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.socialnlp-1.3/}, doi = {10.18653/v1/2023.socialnlp-1.3}, pages = {21--27}, } - VarDialPALI: A Language Identification Benchmark for Perso-Arabic ScriptsSina Ahmadi, Milind Agarwal, and Antonios AnastasopoulosIn Tenth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2023) Code here , May 2023
The Perso-Arabic scripts are a family of scripts that are widely adopted and used by various linguistic communities around the globe. Identifying various languages using such scripts is crucial to language technologies and challenging in low-resource setups. As such, this paper sheds light on the challenges of detecting languages using Perso-Arabic scripts, especially in bilingual communities where “unconventional” writing is practiced. To address this, we use a set of supervised techniques to classify sentences into their languages. Building on these, we also propose a hierarchical model that targets clusters of languages that are more often confused by the classifiers. Our experiment results indicate the effectiveness of our solutions.
@inproceedings{ahmadi-etal-2023-pali, title = {{PALI}: A Language Identification Benchmark for {P}erso-{A}rabic Scripts}, author = {Ahmadi, Sina and Agarwal, Milind and Anastasopoulos, Antonios}, editor = {Scherrer, Yves and Jauhiainen, Tommi and Ljube{\v{s}}i{\'c}, Nikola and Nakov, Preslav and Tiedemann, J{\"o}rg and Zampieri, Marcos}, booktitle = {Tenth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2023)}, month = may, year = {2023}, address = {Dubrovnik, Croatia}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2023.vardial-1.8/}, doi = {10.18653/v1/2023.vardial-1.8}, pages = {78--90}, } - AIES
 True and Fair: Robust and Unbiased Fake News Detection via Interpretable Machine LearningChahat Raj, Anjishnu Mukherjee, and Ziwei ZhuIn Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, Montréal, QC, Canada Code here , May 2023
True and Fair: Robust and Unbiased Fake News Detection via Interpretable Machine LearningChahat Raj, Anjishnu Mukherjee, and Ziwei ZhuIn Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, Montréal, QC, Canada Code here , May 2023The dissemination of information, and consequently, misinformation, occurs at an unprecedented speed, making it increasingly difficult to discern the credibility of rapidly circulating news. Advanced large-scale language models have facilitated the development of classifiers capable of effectively identifying misinformation. Nevertheless, these models are intrinsically susceptible to biases that may be introduced through numerous ways, including contaminated data sources or unfair training methodologies. When trained on biased data, machine learning models may inadvertently learn and reinforce these biases, leading to reduced generalization performance. This situation consequently results in an inherent "unfairness" within the system. Interpretability, referring to the ability to understand and explain the decision-making process of a model, can be used as a tool to explain these biases. Our research aims to identify the root causes of these biases in fake news detection and mitigate their presence using interpretability. We also perform inference time attacks to fairness to validate robustness.
@inproceedings{raj-etal-2023-truefair, author = {Raj, Chahat and Mukherjee, Anjishnu and Zhu, Ziwei}, title = {True and Fair: Robust and Unbiased Fake News Detection via Interpretable Machine Learning}, year = {2023}, isbn = {9798400702310}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3600211.3604760}, doi = {10.1145/3600211.3604760}, booktitle = {Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society}, pages = {962–963}, numpages = {2}, keywords = {bias, fairness, interpretability, misinformation, security}, location = {Montr\'{e}al, QC, Canada}, series = {AIES '23}, } - Zambezi Voice: A Multilingual Speech Corpus for Zambian LanguagesClaytone Sikasote, Kalinda Siaminwe, Stanly Mwape, Bangiwe Zulu, Mofya Phiri, Martin Phiri, David Zulu, Mayumbo Nyirenda, and Antonios AnastasopoulosIn Interspeech 2023, May 2023












2022
- AACL
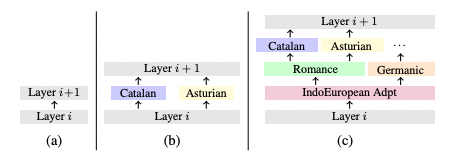 Phylogeny-Inspired Adaptation of Multilingual Models to New LanguagesFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) Code here , Nov 2022
Phylogeny-Inspired Adaptation of Multilingual Models to New LanguagesFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) Code here , Nov 2022Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on a variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal toward expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.
@inproceedings{faisal-anastasopoulos-2022-phylogeny, title = {Phylogeny-Inspired Adaptation of Multilingual Models to New Languages}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {He, Yulan and Ji, Heng and Li, Sujian and Liu, Yang and Chang, Chua-Hui}, booktitle = {Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)}, month = nov, year = {2022}, address = {Online only}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.aacl-main.34/}, doi = {10.18653/v1/2022.aacl-main.34}, pages = {434--452}, } - ACL
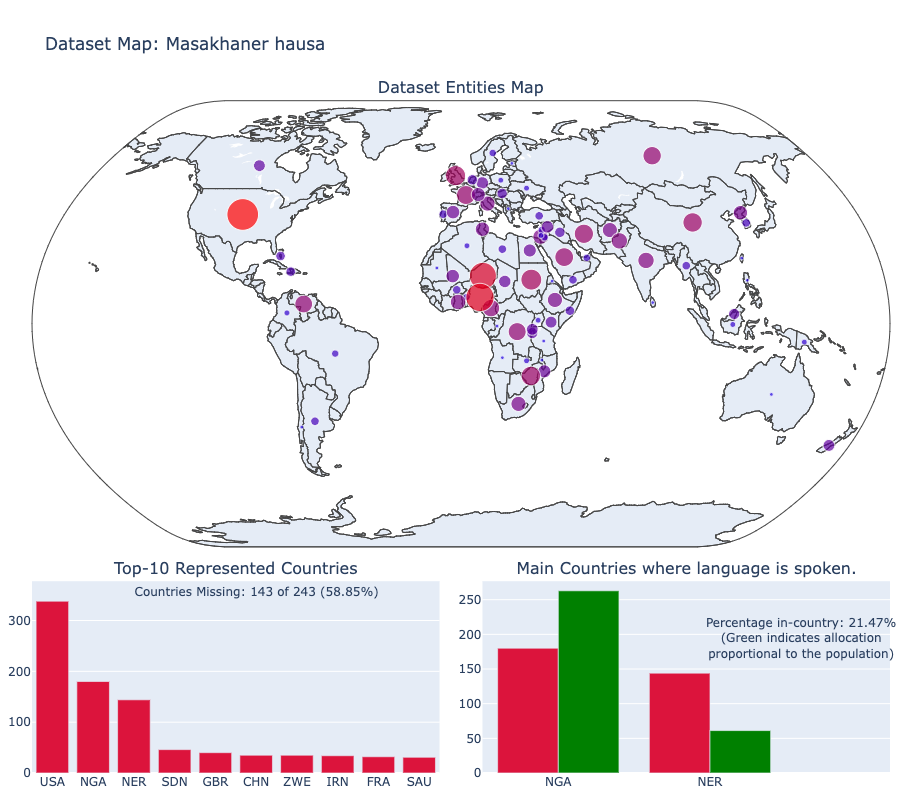 Dataset Geography: Mapping Language Data to Language UsersFahim Faisal, Yinkai Wang, and Antonios AnastasopoulosIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022
Dataset Geography: Mapping Language Data to Language UsersFahim Faisal, Yinkai Wang, and Antonios AnastasopoulosIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022As language technologies become more ubiquitous, there are increasing efforts towards expanding the language diversity and coverage of natural language processing (NLP) systems. Arguably, the most important factor influencing the quality of modern NLP systems is data availability. In this work, we study the geographical representativeness of NLP datasets, aiming to quantify if and by how much do NLP datasets match the expected needs of the language speakers. In doing so, we use entity recognition and linking systems, also making important observations about their cross-lingual consistency and giving suggestions for more robust evaluation. Last, we explore some geographical and economic factors that may explain the observed dataset distributions.
@inproceedings{faisal-etal-2022-dataset, title = {Dataset Geography: Mapping Language Data to Language Users}, author = {Faisal, Fahim and Wang, Yinkai and Anastasopoulos, Antonios}, editor = {Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline}, booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = may, year = {2022}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.acl-long.239/}, doi = {10.18653/v1/2022.acl-long.239}, pages = {3381--3411}, } - ACL
 Systematic Inequalities in Language Technology Performance across the World‘s LanguagesDamian Blasi, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022
Systematic Inequalities in Language Technology Performance across the World‘s LanguagesDamian Blasi, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022Natural language processing (NLP) systems have become a central technology in communication, education, medicine, artificial intelligence, and many other domains of research and development. While the performance of NLP methods has grown enormously over the last decade, this progress has been restricted to a minuscule subset of the world‘s \approx6,500 languages. We introduce a framework for estimating the global utility of language technologies as revealed in a comprehensive snapshot of recent publications in NLP. Our analyses involve the field at large, but also more in-depth studies on both user-facing technologies (machine translation, language understanding, question answering, text-to-speech synthesis) as well as foundational NLP tasks (dependency parsing, morphological inflection). In the process, we (1) quantify disparities in the current state of NLP research, (2) explore some of its associated societal and academic factors, and (3) produce tailored recommendations for evidence-based policy making aimed at promoting more global and equitable language technologies. Data and code to reproduce the findings discussed in this paper areavailable on GitHub (\urlhttps://github.com/neubig/globalutility).
@inproceedings{blasi-etal-2022-systematic, title = {Systematic Inequalities in Language Technology Performance across the World`s Languages}, author = {Blasi, Damian and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline}, booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)}, month = may, year = {2022}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.acl-long.376/}, doi = {10.18653/v1/2022.acl-long.376}, pages = {5486--5505}, } - BEA
 Educational Tools for MapuzugunCristian Ahumada, Claudio Gutierrez, and Antonios AnastasopoulosIn Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022) Code here , Jul 2022
Educational Tools for MapuzugunCristian Ahumada, Claudio Gutierrez, and Antonios AnastasopoulosIn Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022) Code here , Jul 2022Mapuzugun is the language of the Mapuche people. Due to political and historical reasons, its number of speakers has decreased and the language has been excluded from the educational system in Chile and Argentina. For this reason, it is very important to support the revitalization of the Mapuzugun in all spaces and media of society. In this work we present a tool towards supporting educational activities of Mapuzugun, tailored to the characteristics of the language. The tool consists of three parts: design and development of an orthography detector and converter; a morphological analyzer; and an informal translator. We also present a case study with Mapuzugun students showing promising results. Short abstract in Mapuzugun: Tüfachi küzaw pegelfi kiñe zugun küzawpeyüm kelluaetew pu mapuzugun chillkatufe kimal kizu tañi zugun.
@inproceedings{ahumada-etal-2022-educational, title = {Educational Tools for Mapuzugun}, author = {Ahumada, Cristian and Gutierrez, Claudio and Anastasopoulos, Antonios}, editor = {Kochmar, Ekaterina and Burstein, Jill and Horbach, Andrea and Laarmann-Quante, Ronja and Madnani, Nitin and Tack, Ana{\"i}s and Yaneva, Victoria and Yuan, Zheng and Zesch, Torsten}, booktitle = {Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022)}, month = jul, year = {2022}, address = {Seattle, Washington}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.bea-1.23/}, doi = {10.18653/v1/2022.bea-1.23}, pages = {183--196}, } - ACL
 Revisiting the Effects of Leakage on Dependency ParsingNathaniel Krasner*, Miriam Wanner*, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2022 Code here , May 2022
Revisiting the Effects of Leakage on Dependency ParsingNathaniel Krasner*, Miriam Wanner*, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: ACL 2022 Code here , May 2022Recent work by Søgaard (2020) showed that, treebank size aside, overlap between training and test graphs (termed \textitleakage) explains more of the observed variation in dependency parsing performance than other explanations. In this work we revisit this claim, testing it on more models and languages. We find that it only holds for zero-shot cross-lingual settings. We then propose a more fine-grained measure of such leakage which, unlike the original measure, not only explains but also correlates with observed performance variation. Code and data are available here: \urlhttps://github.com/miriamwanner/reu-nlp-project
@inproceedings{krasner-etal-2022-revisiting, title = {Revisiting the Effects of Leakage on Dependency Parsing}, author = {Krasner, Nathaniel and Wanner, Miriam and Anastasopoulos, Antonios}, editor = {Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2022}, month = may, year = {2022}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.findings-acl.230/}, doi = {10.18653/v1/2022.findings-acl.230}, pages = {2925--2934}, } - LREC
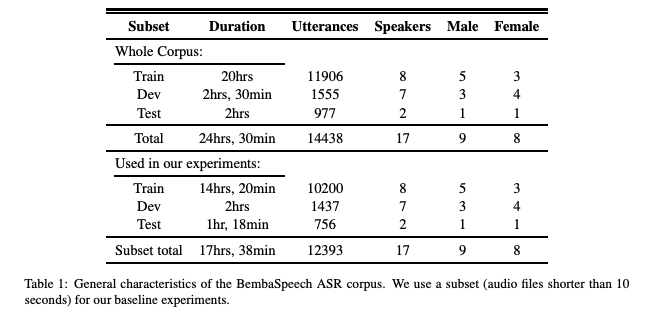 BembaSpeech: A Speech Recognition Corpus for the Bemba LanguageClaytone Sikasote, and Antonios AnastasopoulosIn Proceedings of the Thirteenth Language Resources and Evaluation Conference Code here , Jun 2022
BembaSpeech: A Speech Recognition Corpus for the Bemba LanguageClaytone Sikasote, and Antonios AnastasopoulosIn Proceedings of the Thirteenth Language Resources and Evaluation Conference Code here , Jun 2022We present a preprocessed, ready-to-use automatic speech recognition corpus, BembaSpeech, consisting over 24 hours of read speech in the Bemba language, a written but low-resourced language spoken by over 30% of the population in Zambia. To assess its usefulness for training and testing ASR systems for Bemba, we explored different approaches; supervised pre-training (training from scratch), cross-lingual transfer learning from a monolingual English pre-trained model using DeepSpeech on the portion of the dataset and fine-tuning large scale self-supervised Wav2Vec2.0 based multilingual pre-trained models on the complete BembaSpeech corpus. From our experiments, the 1 billion XLS-R parameter model gives the best results. The model achieves a word error rate (WER) of 32.91%, results demonstrating that model capacity significantly improves performance and that multilingual pre-trained models transfers cross-lingual acoustic representation better than monolingual pre-trained English model on the BembaSpeech for the Bemba ASR. Lastly, results also show that the corpus can be used for building ASR systems for Bemba language.
@inproceedings{sikasote-anastasopoulos-2022-bembaspeech, title = {{B}emba{S}peech: A Speech Recognition Corpus for the {B}emba Language}, author = {Sikasote, Claytone and Anastasopoulos, Antonios}, editor = {Calzolari, Nicoletta and B{\'e}chet, Fr{\'e}d{\'e}ric and Blache, Philippe and Choukri, Khalid and Cieri, Christopher and Declerck, Thierry and Goggi, Sara and Isahara, Hitoshi and Maegaard, Bente and Mariani, Joseph and Mazo, H{\'e}l{\`e}ne and Odijk, Jan and Piperidis, Stelios}, booktitle = {Proceedings of the Thirteenth Language Resources and Evaluation Conference}, month = jun, year = {2022}, address = {Marseille, France}, publisher = {European Language Resources Association}, url = {https://aclanthology.org/2022.lrec-1.790/}, pages = {7277--7283}, } - SIGMORPHONSIGMORPHON–UniMorph 2022 Shared Task 0: Generalization and Typologically Diverse Morphological InflectionJordan Kodner, Salam Khalifa, Khuyagbaatar Batsuren, Hossep Dolatian, Ryan Cotterell, Faruk Akkus, Antonios Anastasopoulos, Taras Andrushko, Aryaman Arora, Nona Atanalov, and 20 more authorsIn Proceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, Jul 2022
The 2022 SIGMORPHON–UniMorph shared task on large scale morphological inflection generation included a wide range of typologically diverse languages: 33 languages from 11 top-level language families: Arabic (Modern Standard), Assamese, Braj, Chukchi, Eastern Armenian, Evenki, Georgian, Gothic, Gujarati, Hebrew, Hungarian, Itelmen, Karelian, Kazakh, Ket, Khalkha Mongolian, Kholosi, Korean, Lamahalot, Low German, Ludic, Magahi, Middle Low German, Old English, Old High German, Old Norse, Polish, Pomak, Slovak, Turkish, Upper Sorbian, Veps, and Xibe. We emphasize generalization along different dimensions this year by evaluating test items with unseen lemmas and unseen features separately under small and large training conditions. Across the five submitted systems and two baselines, the prediction of inflections with unseen features proved challenging, with average performance decreased substantially from last year. This was true even for languages for which the forms were in principle predictable, which suggests that further work is needed in designing systems that capture the various types of generalization required for the world‘s languages.
@inproceedings{kodner-etal-2022-sigmorphon, title = {{SIGMORPHON}{--}{U}ni{M}orph 2022 Shared Task 0: Generalization and Typologically Diverse Morphological Inflection}, author = {Kodner, Jordan and Khalifa, Salam and Batsuren, Khuyagbaatar and Dolatian, Hossep and Cotterell, Ryan and Akkus, Faruk and Anastasopoulos, Antonios and Andrushko, Taras and Arora, Aryaman and Atanalov, Nona and Bella, G{\'a}bor and Budianskaya, Elena and Ghanggo Ate, Yustinus and Goldman, Omer and Guriel, David and Guriel, Simon and Guriel-Agiashvili, Silvia and Kiera{\'s}, Witold and Krizhanovsky, Andrew and Krizhanovsky, Natalia and Marchenko, Igor and Markowska, Magdalena and Mashkovtseva, Polina and Nepomniashchaya, Maria and Rodionova, Daria and Scheifer, Karina and Sorova, Alexandra and Yemelina, Anastasia and Young, Jeremiah and Vylomova, Ekaterina}, editor = {Nicolai, Garrett and Chodroff, Eleanor}, booktitle = {Proceedings of the 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology}, month = jul, year = {2022}, address = {Seattle, Washington}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.sigmorphon-1.19/}, doi = {10.18653/v1/2022.sigmorphon-1.19}, pages = {176--203}, } - SUMEvalThe SUMEval 2022 Shared Task on Performance Prediction of Multilingual Pre-trained Language ModelsKabir Ahuja, Antonios Anastasopoulos, Barun Patra, Graham Neubig, Monojit Choudhury, Sandipan Dandapat, Sunayana Sitaram, and Vishrav ChaudharyIn Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, Nov 2022
@inproceedings{ahuja-etal-2022-sumeval, title = {The {SUME}val 2022 Shared Task on Performance Prediction of Multilingual Pre-trained Language Models}, author = {Ahuja, Kabir and Anastasopoulos, Antonios and Patra, Barun and Neubig, Graham and Choudhury, Monojit and Dandapat, Sandipan and Sitaram, Sunayana and Chaudhary, Vishrav}, editor = {Ahuja, Kabir and Anastasopoulos, Antonios and Patra, Barun and Neubig, Graham and Choudhury, Monojit and Dandapat, Sandipan and Sitaram, Sunayana and Chaudhary, Vishrav}, booktitle = {Proceedings of the First Workshop on Scaling Up Multilingual Evaluation}, month = nov, year = {2022}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.sumeval-1.1/}, doi = {10.18653/v1/2022.sumeval-1.1}, pages = {1--7}, } - SUMEVal
 The GMU System Submission for the SUMEval 2022 Shared TaskSyeda Sabrina Akter, and Antonios AnastasopoulosIn Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, Nov 2022
The GMU System Submission for the SUMEval 2022 Shared TaskSyeda Sabrina Akter, and Antonios AnastasopoulosIn Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, Nov 2022@inproceedings{akter-anastasopoulos-2022-gmu, title = {The {GMU} System Submission for the {SUME}val 2022 Shared Task}, author = {Akter, Syeda Sabrina and Anastasopoulos, Antonios}, editor = {Ahuja, Kabir and Anastasopoulos, Antonios and Patra, Barun and Neubig, Graham and Choudhury, Monojit and Dandapat, Sandipan and Sitaram, Sunayana and Chaudhary, Vishrav}, booktitle = {Proceedings of the First Workshop on Scaling Up Multilingual Evaluation}, month = nov, year = {2022}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.sumeval-1.3/}, doi = {10.18653/v1/2022.sumeval-1.3}, pages = {13--20}, } - VarDialFindings of the VarDial Evaluation Campaign 2022Noëmi Aepli, Antonios Anastasopoulos, Adrian-Gabriel Chifu, William Domingues, Fahim Faisal, Mihaela Gaman, Radu Tudor Ionescu, and Yves ScherrerIn Proceedings of the Ninth Workshop on NLP for Similar Languages, Varieties and Dialects, Oct 2022
This report presents the results of the shared tasks organized as part of the VarDial Evaluation Campaign 2022. The campaign is part of the ninth workshop on Natural Language Processing (NLP) for Similar Languages, Varieties and Dialects (VarDial), co-located with COLING 2022. Three separate shared tasks were included this year: Identification of Languages and Dialects of Italy (ITDI), French Cross-Domain Dialect Identification (FDI), and Dialectal Extractive Question Answering (DialQA). All three tasks were organized for the first time this year.
@inproceedings{aepli-etal-2022-findings, title = {Findings of the {V}ar{D}ial Evaluation Campaign 2022}, author = {Aepli, No{\"e}mi and Anastasopoulos, Antonios and Chifu, Adrian-Gabriel and Domingues, William and Faisal, Fahim and Gaman, Mihaela and Ionescu, Radu Tudor and Scherrer, Yves}, editor = {Scherrer, Yves and Jauhiainen, Tommi and Ljube{\v{s}}i{\'c}, Nikola and Nakov, Preslav and Tiedemann, J{\"o}rg and Zampieri, Marcos}, booktitle = {Proceedings of the Ninth Workshop on NLP for Similar Languages, Varieties and Dialects}, month = oct, year = {2022}, address = {Gyeongju, Republic of Korea}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.vardial-1.1/}, pages = {1--13}, } - WMTLanguage Adapters for Large-Scale MT: The GMU System for the WMT 2022 Large-Scale Machine Translation Evaluation for African Languages Shared TaskMd Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the Seventh Conference on Machine Translation (WMT), Dec 2022
This report describes GMU‘s machine translation systems for the WMT22 shared task on large-scale machine translation evaluation for African languages. We participated in the constrained translation track where only the data listed on the shared task page were allowed, including submissions accepted to the Data track. Our approach uses models initialized with DeltaLM, a generic pre-trained multilingual encoder-decoder model, and fine-tuned correspondingly with the allowed data sources. Our best submission incorporates language family and language-specific adapter units; ranking ranked second under the constrained setting.
@inproceedings{alam-anastasopoulos-2022-language, title = {Language Adapters for Large-Scale {MT}: The {GMU} System for the {WMT} 2022 Large-Scale Machine Translation Evaluation for {A}frican Languages Shared Task}, author = {Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Koehn, Philipp and Barrault, Lo{\"i}c and Bojar, Ond{\v{r}}ej and Bougares, Fethi and Chatterjee, Rajen and Costa-juss{\`a}, Marta R. and Federmann, Christian and Fishel, Mark and Fraser, Alexander and Freitag, Markus and Graham, Yvette and Grundkiewicz, Roman and Guzman, Paco and Haddow, Barry and Huck, Matthias and Jimeno Yepes, Antonio and Kocmi, Tom and Martins, Andr{\'e} and Morishita, Makoto and Monz, Christof and Nagata, Masaaki and Nakazawa, Toshiaki and Negri, Matteo and N{\'e}v{\'e}ol, Aur{\'e}lie and Neves, Mariana and Popel, Martin and Turchi, Marco and Zampieri, Marcos}, booktitle = {Proceedings of the Seventh Conference on Machine Translation (WMT)}, month = dec, year = {2022}, address = {Abu Dhabi, United Arab Emirates (Hybrid)}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.wmt-1.99/}, pages = {1015--1033}, }







2021
- ACL
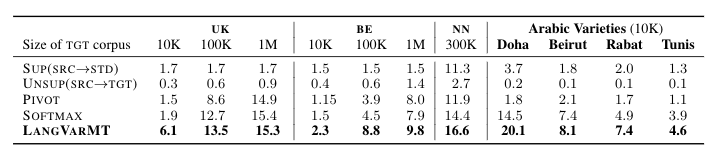 Machine Translation into Low-resource Language VarietiesSachin Kumar, Antonios Anastasopoulos, Shuly Wintner, and Yulia TsvetkovIn Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021
Machine Translation into Low-resource Language VarietiesSachin Kumar, Antonios Anastasopoulos, Shuly Wintner, and Yulia TsvetkovIn Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021State-of-the-art machine translation (MT) systems are typically trained to generate “standard” target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source–variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English–Russian MT system to generate Ukrainian and Belarusian, an English–Norwegian Bokmål system to generate Nynorsk, and an English–Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.
@inproceedings{kumar-etal-2021-machine, title = {Machine Translation into Low-resource Language Varieties}, author = {Kumar, Sachin and Anastasopoulos, Antonios and Wintner, Shuly and Tsvetkov, Yulia}, editor = {Zong, Chengqing and Xia, Fei and Li, Wenjie and Navigli, Roberto}, booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.acl-short.16/}, doi = {10.18653/v1/2021.acl-short.16}, pages = {110--121}, } - ACL
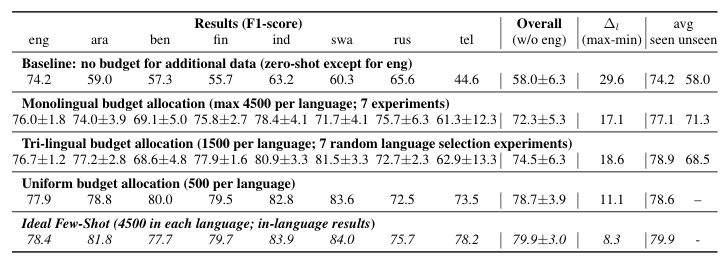 Towards more equitable question answering systems: How much more data do you need?Arnab Debnath*, Navid Rajabi*, Fardina Fathmiul Alam*, and Antonios AnastasopoulosIn Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021
Towards more equitable question answering systems: How much more data do you need?Arnab Debnath*, Navid Rajabi*, Fardina Fathmiul Alam*, and Antonios AnastasopoulosIn Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021Question answering (QA) in English has been widely explored, but multilingual datasets are relatively new, with several methods attempting to bridge the gap between high- and low-resourced languages using data augmentation through translation and cross-lingual transfer. In this project we take a step back and study which approaches allow us to take the most advantage of existing resources in order to produce QA systems in many languages. Specifically, we perform extensive analysis to measure the efficacy of few-shot approaches augmented with automatic translations and permutations of context-question-answer pairs. In addition, we make suggestions for future dataset development efforts that make better use of a fixed annotation budget, with a goal of increasing the language coverage of QA datasets and systems.
@inproceedings{debnath-etal-2021-towards, title = {Towards more equitable question answering systems: How much more data do you need?}, author = {Debnath, Arnab and Rajabi, Navid and Alam, Fardina Fathmiul and Anastasopoulos, Antonios}, editor = {Zong, Chengqing and Xia, Fei and Li, Wenjie and Navigli, Roberto}, booktitle = {Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.acl-short.79/}, doi = {10.18653/v1/2021.acl-short.79}, pages = {621--629}, } - EMNLP
 When is Wall a Pared and when a Muro?: Extracting Rules Governing Lexical SelectionAditi Chaudhary, Kayo Yin, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Code here , Nov 2021
When is Wall a Pared and when a Muro?: Extracting Rules Governing Lexical SelectionAditi Chaudhary, Kayo Yin, Antonios Anastasopoulos, and Graham NeubigIn Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Code here , Nov 2021Learning fine-grained distinctions between vocabulary items is a key challenge in learning a new language. For example, the noun “wall” has different lexical manifestations in Spanish – “pared” refers to an indoor wall while “muro” refers to an outside wall. However, this variety of lexical distinction may not be obvious to non-native learners unless the distinction is explained in such a way. In this work, we present a method for automatically identifying fine-grained lexical distinctions, and extracting rules explaining these distinctions in a human- and machine-readable format. We confirm the quality of these extracted rules in a language learning setup for two languages, Spanish and Greek, where we use the rules to teach non-native speakers when to translate a given ambiguous word into its different possible translations.
@inproceedings{chaudhary-etal-2021-wall, title = {When is Wall a Pared and when a Muro?: Extracting Rules Governing Lexical Selection}, author = {Chaudhary, Aditi and Yin, Kayo and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Moens, Marie-Francine and Huang, Xuanjing and Specia, Lucia and Yih, Scott Wen-tau}, booktitle = {Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2021}, address = {Online and Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.emnlp-main.553/}, doi = {10.18653/v1/2021.emnlp-main.553}, pages = {6911--6929}, } - EMNLP
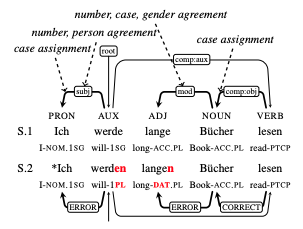 Evaluating the Morphosyntactic Well-formedness of Generated TextsAdithya Pratapa*, Antonios Anastasopoulos*, Shruti Rijhwani, Aditi Chaudhary, David R. Mortensen, Graham Neubig, and Yulia TsvetkovIn Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Code here , Nov 2021
Evaluating the Morphosyntactic Well-formedness of Generated TextsAdithya Pratapa*, Antonios Anastasopoulos*, Shruti Rijhwani, Aditi Chaudhary, David R. Mortensen, Graham Neubig, and Yulia TsvetkovIn Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Code here , Nov 2021Text generation systems are ubiquitous in natural language processing applications. However, evaluation of these systems remains a challenge, especially in multilingual settings. In this paper, we propose L‘AMBRE – a metric to evaluate the morphosyntactic well-formedness of text using its dependency parse and morphosyntactic rules of the language. We present a way to automatically extract various rules governing morphosyntax directly from dependency treebanks. To tackle the noisy outputs from text generation systems, we propose a simple methodology to train robust parsers. We show the effectiveness of our metric on the task of machine translation through a diachronic study of systems translating into morphologically-rich languages.
@inproceedings{pratapa-etal-2021-evaluating, title = {Evaluating the Morphosyntactic Well-formedness of Generated Texts}, author = {Pratapa, Adithya and Anastasopoulos, Antonios and Rijhwani, Shruti and Chaudhary, Aditi and Mortensen, David R. and Neubig, Graham and Tsvetkov, Yulia}, editor = {Moens, Marie-Francine and Huang, Xuanjing and Specia, Lucia and Yih, Scott Wen-tau}, booktitle = {Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing}, month = nov, year = {2021}, address = {Online and Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.emnlp-main.570/}, doi = {10.18653/v1/2021.emnlp-main.570}, pages = {7131--7150}, } - EMNLP
 SD-QA: Spoken Dialectal Question Answering for the Real WorldFahim Faisal, Sharlina Keshava, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EMNLP 2021 Code here , Nov 2021
SD-QA: Spoken Dialectal Question Answering for the Real WorldFahim Faisal, Sharlina Keshava, Md Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Findings of the Association for Computational Linguistics: EMNLP 2021 Code here , Nov 2021Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations.
@inproceedings{faisal-etal-2021-sd-qa, title = {{SD}-{QA}: Spoken Dialectal Question Answering for the Real World}, author = {Faisal, Fahim and Keshava, Sharlina and Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Moens, Marie-Francine and Huang, Xuanjing and Specia, Lucia and Yih, Scott Wen-tau}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2021}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.findings-emnlp.281/}, doi = {10.18653/v1/2021.findings-emnlp.281}, pages = {3296--3315}, } - MRL
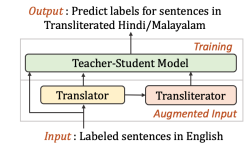 Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot FillingJitin Krishnan, Antonios Anastasopoulos, Hemant Purohit, and Huzefa RangwalaIn Proceedings of the 1st Workshop on Multilingual Representation Learning Code here , Nov 2021
Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot FillingJitin Krishnan, Antonios Anastasopoulos, Hemant Purohit, and Huzefa RangwalaIn Proceedings of the 1st Workshop on Multilingual Representation Learning Code here , Nov 2021Predicting user intent and detecting the corresponding slots from text are two key problems in Natural Language Understanding (NLU). Since annotated datasets are only available for a handful of languages, our work focuses particularly on a zero-shot scenario where the target language is unseen during training. In the context of zero-shot learning, this task is typically approached using representations from pre-trained multilingual language models such as mBERT or by fine-tuning on data automatically translated into the target language. We propose a novel method which augments monolingual source data using multilingual code-switching via random translations, to enhance generalizability of large multilingual language models when fine-tuning them for downstream tasks. Experiments on the MultiATIS++ benchmark show that our method leads to an average improvement of +4.2% in accuracy for the intent task and +1.8% in F1 for the slot-filling task over the state-of-the-art across 8 typologically diverse languages. We also study the impact of code-switching into different families of languages on downstream performance. Furthermore, we present an application of our method for crisis informatics using a new human-annotated tweet dataset of slot filling in English and Haitian Creole, collected during the Haiti earthquake.
@inproceedings{krishnan-etal-2021-multilingual, title = {Multilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot Filling}, author = {Krishnan, Jitin and Anastasopoulos, Antonios and Purohit, Hemant and Rangwala, Huzefa}, editor = {Ataman, Duygu and Birch, Alexandra and Conneau, Alexis and Firat, Orhan and Ruder, Sebastian and Sahin, Gozde Gul}, booktitle = {Proceedings of the 1st Workshop on Multilingual Representation Learning}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.mrl-1.18/}, doi = {10.18653/v1/2021.mrl-1.18}, pages = {211--223}, } - MRQAInvestigating Post-pretraining Representation Alignment for Cross-Lingual Question AnsweringFahim Faisal, and Antonios AnastasopoulosIn Proceedings of the 3rd Workshop on Machine Reading for Question Answering Code here , Nov 2021
Human knowledge is collectively encoded in the roughly 6500 languages spoken around the world, but it is not distributed equally across languages. Hence, for information-seeking question answering (QA) systems to adequately serve speakers of all languages, they need to operate cross-lingually. In this work we investigate the capabilities of multilingually pretrained language models on cross-lingual QA. We find that explicitly aligning the representations across languages with a post-hoc finetuning step generally leads to improved performance. We additionally investigate the effect of data size as well as the language choice in this fine-tuning step, also releasing a dataset for evaluating cross-lingual QA systems.
@inproceedings{faisal-anastasopoulos-2021-investigating, title = {Investigating Post-pretraining Representation Alignment for Cross-Lingual Question Answering}, author = {Faisal, Fahim and Anastasopoulos, Antonios}, editor = {Fisch, Adam and Talmor, Alon and Chen, Danqi and Choi, Eunsol and Seo, Minjoon and Lewis, Patrick and Jia, Robin and Min, Sewon}, booktitle = {Proceedings of the 3rd Workshop on Machine Reading for Question Answering}, month = nov, year = {2021}, address = {Punta Cana, Dominican Republic}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.mrqa-1.14/}, doi = {10.18653/v1/2021.mrqa-1.14}, pages = {133--148}, } - NAACL
 When Being Unseen from mBERT is just the Beginning: Handling New Languages With Multilingual Language ModelsBenjamin Muller, Antonios Anastasopoulos, Benoît Sagot, and Djamé SeddahIn Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Code here , Jun 2021
When Being Unseen from mBERT is just the Beginning: Handling New Languages With Multilingual Language ModelsBenjamin Muller, Antonios Anastasopoulos, Benoît Sagot, and Djamé SeddahIn Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Code here , Jun 2021Transfer learning based on pretraining language models on a large amount of raw data has become a new norm to reach state-of-the-art performance in NLP. Still, it remains unclear how this approach should be applied for unseen languages that are not covered by any available large-scale multilingual language model and for which only a small amount of raw data is generally available. In this work, by comparing multilingual and monolingual models, we show that such models behave in multiple ways on unseen languages. Some languages greatly benefit from transfer learning and behave similarly to closely related high resource languages whereas others apparently do not. Focusing on the latter, we show that this failure to transfer is largely related to the impact of the script used to write such languages. We show that transliterating those languages significantly improves the potential of large-scale multilingual language models on downstream tasks. This result provides a promising direction towards making these massively multilingual models useful for a new set of unseen languages.
@inproceedings{muller-etal-2021-unseen, title = {When Being Unseen from m{BERT} is just the Beginning: Handling New Languages With Multilingual Language Models}, author = {Muller, Benjamin and Anastasopoulos, Antonios and Sagot, Beno{\i}t and Seddah, Djam{\'e}}, editor = {Toutanova, Kristina and Rumshisky, Anna and Zettlemoyer, Luke and Hakkani-Tur, Dilek and Beltagy, Iz and Bethard, Steven and Cotterell, Ryan and Chakraborty, Tanmoy and Zhou, Yichao}, booktitle = {Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies}, month = jun, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.naacl-main.38/}, doi = {10.18653/v1/2021.naacl-main.38}, pages = {448--462}, } - NLP4ProgCode to Comment Translation: A Comparative Study on Model Effectiveness & ErrorsJunayed Mahmud, Fahim Faisal, Raihan Islam Arnob, Antonios Anastasopoulos, and Kevin MoranIn Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) Code here , Aug 2021
Automated source code summarization is a popular software engineering research topic wherein machine translation models are employed to “translate” code snippets into relevant natural language descriptions. Most evaluations of such models are conducted using automatic reference-based metrics. However, given the relatively large semantic gap between programming languages and natural language, we argue that this line of research would benefit from a qualitative investigation into the various error modes of current state-of-the-art models. Therefore, in this work, we perform both a quantitative and qualitative comparison of three recently proposed source code summarization models. In our quantitative evaluation, we compare the models based on the smoothed BLEU-4, METEOR, and ROUGE-L machine translation metrics, and in our qualitative evaluation, we perform a manual open-coding of the most common errors committed by the models when compared to ground truth captions. Our investigation reveals new insights into the relationship between metric-based performance and model prediction errors grounded in an error taxonomy that can be used to drive future research efforts.
@inproceedings{mahmud-etal-2021-code, title = {Code to Comment Translation: A Comparative Study on Model Effectiveness {\&} Errors}, author = {Mahmud, Junayed and Faisal, Fahim and Arnob, Raihan Islam and Anastasopoulos, Antonios and Moran, Kevin}, editor = {Lachmy, Royi and Yao, Ziyu and Durrett, Greg and Gligoric, Milos and Li, Junyi Jessy and Mooney, Ray and Neubig, Graham and Su, Yu and Sun, Huan and Tsarfaty, Reut}, booktitle = {Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021)}, month = aug, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.nlp4prog-1.1/}, doi = {10.18653/v1/2021.nlp4prog-1.1}, pages = {1--16}, } - TACL
 Reducing Confusion in Active Learning for Part-Of-Speech TaggingAditi Chaudhary, Antonios Anastasopoulos, Zaid Sheikh, and Graham NeubigTransactions of the Association for Computational Linguistics Code here , Aug 2021
Reducing Confusion in Active Learning for Part-Of-Speech TaggingAditi Chaudhary, Antonios Anastasopoulos, Zaid Sheikh, and Graham NeubigTransactions of the Association for Computational Linguistics Code here , Aug 2021Active learning (AL) uses a data selection algorithm to select useful training samples to minimize annotation cost. This is now an essential tool for building low-resource syntactic analyzers such as part-of-speech (POS) taggers. Existing AL heuristics are generally designed on the principle of selecting uncertain yet representative training instances, where annotating these instances may reduce a large number of errors. However, in an empirical study across six typologically diverse languages (German, Swedish, Galician, North Sami, Persian, and Ukrainian), we found the surprising result that even in an oracle scenario where we know the true uncertainty of predictions, these current heuristics are far from optimal. Based on this analysis, we pose the problem of AL as selecting instances that maximally reduce the confusion between particular pairs of output tags. Extensive experimentation on the aforementioned languages shows that our proposed AL strategy outperforms other AL strategies by a significant margin. We also present auxiliary results demonstrating the importance of proper calibration of models, which we ensure through cross-view training, and analysis demonstrating how our proposed strategy selects examples that more closely follow the oracle data distribution. The code is publicly released here.1
@article{chaudhary-etal-2021-reducing, title = {Reducing Confusion in Active Learning for Part-Of-Speech Tagging}, author = {Chaudhary, Aditi and Anastasopoulos, Antonios and Sheikh, Zaid and Neubig, Graham}, editor = {Roark, Brian and Nenkova, Ani}, journal = {Transactions of the Association for Computational Linguistics}, volume = {9}, year = {2021}, address = {Cambridge, MA}, publisher = {MIT Press}, url = {https://aclanthology.org/2021.tacl-1.1/}, doi = {10.1162/tacl_a_00350}, pages = {1--16}, } - TACL
 Lexically Aware Semi-Supervised Learning for OCR Post-CorrectionShruti Rijhwani, Daisy Rosenblum, Antonios Anastasopoulos, and Graham NeubigTransactions of the Association for Computational Linguistics Code here , Aug 2021
Lexically Aware Semi-Supervised Learning for OCR Post-CorrectionShruti Rijhwani, Daisy Rosenblum, Antonios Anastasopoulos, and Graham NeubigTransactions of the Association for Computational Linguistics Code here , Aug 2021Much of the existing linguistic data in many languages of the world is locked away in non- digitized books and documents. Optical character recognition (OCR) can be used to produce digitized text, and previous work has demonstrated the utility of neural post-correction methods that improve the results of general- purpose OCR systems on recognition of less- well-resourced languages. However, these methods rely on manually curated post- correction data, which are relatively scarce compared to the non-annotated raw images that need to be digitized. In this paper, we present a semi-supervised learning method that makes it possible to utilize these raw images to improve performance, specifically through the use of self-training, a technique where a model is iteratively trained on its own outputs. In addition, to enforce consistency in the recognized vocabulary, we introduce a lexically aware decoding method that augments the neural post-correction model with a count-based language model constructed from the recognized texts, implemented using weighted finite-state automata (WFSA) for efficient and effective decoding. Results on four endangered languages demonstrate the utility of the proposed method, with relative error reductions of 15%–29%, where we find the combination of self-training and lexically aware decoding essential for achieving consistent improvements.
@article{rijhwani-etal-2021-lexically, title = {Lexically Aware Semi-Supervised Learning for {OCR} Post-Correction}, author = {Rijhwani, Shruti and Rosenblum, Daisy and Anastasopoulos, Antonios and Neubig, Graham}, editor = {Roark, Brian and Nenkova, Ani}, journal = {Transactions of the Association for Computational Linguistics}, volume = {9}, year = {2021}, address = {Cambridge, MA}, publisher = {MIT Press}, url = {https://aclanthology.org/2021.tacl-1.76/}, doi = {10.1162/tacl_a_00427}, pages = {1285--1302}, } - WMTFindings of the WMT Shared Task on Machine Translation Using TerminologiesMd Mahfuz Ibn Alam, Ivana Kvapilíková, Antonios Anastasopoulos, Laurent Besacier, Georgiana Dinu, Marcello Federico, Matthias Gallé, Kweonwoo Jung, Philipp Koehn, and Vassilina NikoulinaIn Proceedings of the Sixth Conference on Machine Translation, Nov 2021
Language domains that require very careful use of terminology are abundant and reflect a significant part of the translation industry. In this work we introduce a benchmark for evaluating the quality and consistency of terminology translation, focusing on the medical (and COVID-19 specifically) domain for five language pairs: English to French, Chinese, Russian, and Korean, as well as Czech to German. We report the descriptions and results of the participating systems, commenting on the need for further research efforts towards both more adequate handling of terminologies as well as towards a proper formulation and evaluation of the task.
@inproceedings{alam-etal-2021-findings, title = {Findings of the {WMT} Shared Task on Machine Translation Using Terminologies}, author = {Alam, Md Mahfuz Ibn and Kvapil{\'i}kov{\'a}, Ivana and Anastasopoulos, Antonios and Besacier, Laurent and Dinu, Georgiana and Federico, Marcello and Gall{\'e}, Matthias and Jung, Kweonwoo and Koehn, Philipp and Nikoulina, Vassilina}, editor = {Barrault, Loic and Bojar, Ondrej and Bougares, Fethi and Chatterjee, Rajen and Costa-jussa, Marta R. and Federmann, Christian and Fishel, Mark and Fraser, Alexander and Freitag, Markus and Graham, Yvette and Grundkiewicz, Roman and Guzman, Paco and Haddow, Barry and Huck, Matthias and Yepes, Antonio Jimeno and Koehn, Philipp and Kocmi, Tom and Martins, Andre and Morishita, Makoto and Monz, Christof}, booktitle = {Proceedings of the Sixth Conference on Machine Translation}, month = nov, year = {2021}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2021.wmt-1.69/}, pages = {652--663}, }









2020
- W-NUT
 Fine-Tuning MT systems for Robustness to Second-Language Speaker VariationsMd Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020) Code here , Nov 2020
Fine-Tuning MT systems for Robustness to Second-Language Speaker VariationsMd Mahfuz Ibn Alam, and Antonios AnastasopoulosIn Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020) Code here , Nov 2020Best Research Paper Award (1 of 2)
The performance of neural machine translation (NMT) systems only trained on a single language variant degrades when confronted with even slightly different language variations. With this work, we build upon previous work to explore how to mitigate this issue. We show that fine-tuning using naturally occurring noise along with pseudo-references (i.e. “corrected” non-native inputs translated using the baseline NMT system) is a promising solution towards systems robust to such type of input variations. We focus on four translation pairs, from English to Spanish, Italian, French, and Portuguese, with our system achieving improvements of up to 3.1 BLEU points compared to the baselines, establishing a new state-of-the-art on the JFLEG-ES dataset. All datasets and code are publicly available here: \urlhttps://github.com/mahfuzibnalam/finetuning_for_robustness .
@inproceedings{alam-anastasopoulos-2020-fine, title = {Fine-Tuning {MT} systems for Robustness to Second-Language Speaker Variations}, author = {Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios}, editor = {Xu, Wei and Ritter, Alan and Baldwin, Tim and Rahimi, Afshin}, booktitle = {Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020)}, month = nov, year = {2020}, address = {Online}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2020.wnut-1.20/}, doi = {10.18653/v1/2020.wnut-1.20}, pages = {149--158}, }

1905
- Ann. Phys.Über einen die Erzeugung und Verwandlung des Lichtes betreffenden heuristischen GesichtspunktAlbert EinsteinAnn. Phys., Nov 1905
Albert Einstein receveid the Nobel Prize in Physics 1921 for his services to Theoretical Physics, and especially for his discovery of the law of the photoelectric effect
This is the abstract text.
@article{einstein1905photoelectriceffect, title = {{{\"U}ber einen die Erzeugung und Verwandlung des Lichtes betreffenden heuristischen Gesichtspunkt}}, author = {Einstein, Albert}, journal = {Ann. Phys.}, volume = {322}, number = {6}, pages = {132--148}, year = {1905}, doi = {10.1002/andp.19053220607}, }