Quantifying and Mitigating Disparities in Language Technologies
funded by the NSF (2021-2024)
Project Description
Advances in natural language processing (NLP) technology now make it possible to perform many tasks through natural language or over natural language data – automatic systems can answer questions, perform web search, or command our computers to perform specific tasks. However, “language” is not monolithic; people vary in the language they speak, the dialect they use, the relative ease with which they produce language, or the words they choose with which to express themselves. In benchmarking of NLP systems however, this linguistic variety is generally unattested. Most commonly tasks are formulated using canonical American English, designed with little regard for whether systems will work on language of any other variety. In this work we ask a simple question: can we measure the extent to which the diversity of language that we use affects the quality of results that we can expect from language technology systems? This will allow for the development and deployment of fair accuracy measures for a variety of tasks regarding language technology, encouraging advances in the state of the art in these technologies to focus on all, not just a select few.
Specifically, this work focuses on four aspects of this overall research question. First, we will develop a general-purpose methodology for quantifying how well particular language technologies work across many varieties of language. Measures over multiple speakers or demographics are combined to benchmarks that can drive progress in development of fair metrics for language systems, tailored to the specific needs of design teams. Second, we will move beyond simple accuracy measures, and directly quantify the effect that the accuracy of systems has on users in terms of relative utility derived from using the system. These measures of utility will be incorporated in our metrics for system success. Third, we focus on the language produced by people from varying demographic groups, predicting system accuracies from demographics. Finally, we will examine novel methods for robust learning of NLP systems across language or dialectal boundaries, and examine the effect that these methods have on increasing accuracy for all users.
Recent advances in the capacity of large language models to generate human-like text have resulted in their increased adoption in user-facing settings. In parallel, these improvements have prompted a heated discourse around the risks of societal harms they introduce, whether inadvertent or malicious. Several studies have explored these harms and called for their mitigation via development of safer, fairer models. Going beyond enumerating the risks of harms, this work provides a survey of practical methods for addressing potential threats and societal harms from language generation models. We draw on several prior works’ taxonomies of language model risks to present a structured overview of strategies for detecting and ameliorating different kinds of risks/harms of language generators. Bridging diverse strands of research, this survey aims to serve as a practical guide for both LM researchers and practitioners, with explanations of different strategies’ motivations, their limitations, and open problems for future research.
@inproceedings{kumar-etal-2023-language,title={Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey},author={Kumar, Sachin and Balachandran, Vidhisha and Njoo, Lucille and Anastasopoulos, Antonios and Tsvetkov, Yulia},editor={Vlachos, Andreas and Augenstein, Isabelle},booktitle={Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics},month=may,year={2023},address={Dubrovnik, Croatia},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2023.eacl-main.241/},doi={10.18653/v1/2023.eacl-main.241},pages={3299--3321},}
2022
ACL
Systematic Inequalities in Language Technology Performance across the World‘s Languages
Damian Blasi, Antonios Anastasopoulos, and Graham Neubig
In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022
Natural language processing (NLP) systems have become a central technology in communication, education, medicine, artificial intelligence, and many other domains of research and development. While the performance of NLP methods has grown enormously over the last decade, this progress has been restricted to a minuscule subset of the world‘s \approx6,500 languages. We introduce a framework for estimating the global utility of language technologies as revealed in a comprehensive snapshot of recent publications in NLP. Our analyses involve the field at large, but also more in-depth studies on both user-facing technologies (machine translation, language understanding, question answering, text-to-speech synthesis) as well as foundational NLP tasks (dependency parsing, morphological inflection). In the process, we (1) quantify disparities in the current state of NLP research, (2) explore some of its associated societal and academic factors, and (3) produce tailored recommendations for evidence-based policy making aimed at promoting more global and equitable language technologies. Data and code to reproduce the findings discussed in this paper areavailable on GitHub (\urlhttps://github.com/neubig/globalutility).
@inproceedings{blasi-etal-2022-systematic,title={Systematic Inequalities in Language Technology Performance across the World`s Languages},author={Blasi, Damian and Anastasopoulos, Antonios and Neubig, Graham},editor={Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline},booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},month=may,year={2022},address={Dublin, Ireland},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2022.acl-long.376/},doi={10.18653/v1/2022.acl-long.376},pages={5486--5505},}
ACL
Dataset Geography: Mapping Language Data to Language Users
Fahim Faisal, Yinkai Wang, and Antonios Anastasopoulos
In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Code here , May 2022
As language technologies become more ubiquitous, there are increasing efforts towards expanding the language diversity and coverage of natural language processing (NLP) systems. Arguably, the most important factor influencing the quality of modern NLP systems is data availability. In this work, we study the geographical representativeness of NLP datasets, aiming to quantify if and by how much do NLP datasets match the expected needs of the language speakers. In doing so, we use entity recognition and linking systems, also making important observations about their cross-lingual consistency and giving suggestions for more robust evaluation. Last, we explore some geographical and economic factors that may explain the observed dataset distributions.
@inproceedings{faisal-etal-2022-dataset,title={Dataset Geography: Mapping Language Data to Language Users},author={Faisal, Fahim and Wang, Yinkai and Anastasopoulos, Antonios},editor={Muresan, Smaranda and Nakov, Preslav and Villavicencio, Aline},booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},month=may,year={2022},address={Dublin, Ireland},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2022.acl-long.239/},doi={10.18653/v1/2022.acl-long.239},pages={3381--3411},}
2021
ACL
Towards more equitable question answering systems: How much more data do you need?
Arnab Debnath*, Navid Rajabi*, Fardina Fathmiul Alam*, and Antonios Anastasopoulos
In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021
Question answering (QA) in English has been widely explored, but multilingual datasets are relatively new, with several methods attempting to bridge the gap between high- and low-resourced languages using data augmentation through translation and cross-lingual transfer. In this project we take a step back and study which approaches allow us to take the most advantage of existing resources in order to produce QA systems in many languages. Specifically, we perform extensive analysis to measure the efficacy of few-shot approaches augmented with automatic translations and permutations of context-question-answer pairs. In addition, we make suggestions for future dataset development efforts that make better use of a fixed annotation budget, with a goal of increasing the language coverage of QA datasets and systems.
@inproceedings{debnath-etal-2021-towards,title={Towards more equitable question answering systems: How much more data do you need?},author={Debnath, Arnab and Rajabi, Navid and Alam, Fardina Fathmiul and Anastasopoulos, Antonios},editor={Zong, Chengqing and Xia, Fei and Li, Wenjie and Navigli, Roberto},booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)},month=aug,year={2021},address={Online},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2021.acl-short.79/},doi={10.18653/v1/2021.acl-short.79},pages={621--629},}
EMNLP
SD-QA: Spoken Dialectal Question Answering for the Real World
Fahim Faisal, Sharlina Keshava, Md Mahfuz Ibn Alam, and Antonios Anastasopoulos
In Findings of the Association for Computational Linguistics: EMNLP 2021 Code here , Nov 2021
Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations.
@inproceedings{faisal-etal-2021-sd-qa,title={{SD}-{QA}: Spoken Dialectal Question Answering for the Real World},author={Faisal, Fahim and Keshava, Sharlina and Alam, Md Mahfuz Ibn and Anastasopoulos, Antonios},editor={Moens, Marie-Francine and Huang, Xuanjing and Specia, Lucia and Yih, Scott Wen-tau},booktitle={Findings of the Association for Computational Linguistics: EMNLP 2021},month=nov,year={2021},address={Punta Cana, Dominican Republic},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2021.findings-emnlp.281/},doi={10.18653/v1/2021.findings-emnlp.281},pages={3296--3315},}
ACL
Machine Translation into Low-resource Language Varieties
Sachin Kumar, Antonios Anastasopoulos, Shuly Wintner, and Yulia Tsvetkov
In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021
State-of-the-art machine translation (MT) systems are typically trained to generate “standard” target language; however, many languages have multiple varieties (regional varieties, dialects, sociolects, non-native varieties) that are different from the standard language. Such varieties are often low-resource, and hence do not benefit from contemporary NLP solutions, MT included. We propose a general framework to rapidly adapt MT systems to generate language varieties that are close to, but different from, the standard target language, using no parallel (source–variety) data. This also includes adaptation of MT systems to low-resource typologically-related target languages. We experiment with adapting an English–Russian MT system to generate Ukrainian and Belarusian, an English–Norwegian Bokmål system to generate Nynorsk, and an English–Arabic system to generate four Arabic dialects, obtaining significant improvements over competitive baselines.
@inproceedings{kumar-etal-2021-machine,title={Machine Translation into Low-resource Language Varieties},author={Kumar, Sachin and Anastasopoulos, Antonios and Wintner, Shuly and Tsvetkov, Yulia},editor={Zong, Chengqing and Xia, Fei and Li, Wenjie and Navigli, Roberto},booktitle={Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)},month=aug,year={2021},address={Online},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2021.acl-short.16/},doi={10.18653/v1/2021.acl-short.16},pages={110--121},}



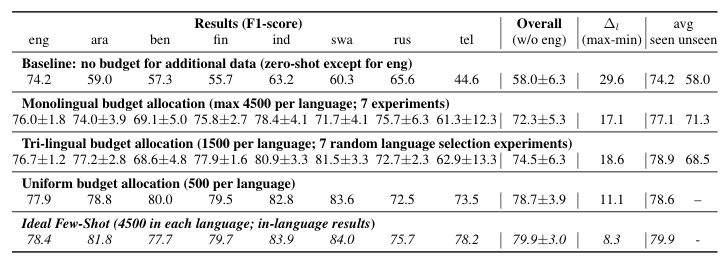 Towards more equitable question answering systems: How much more data do you need?In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021
Towards more equitable question answering systems: How much more data do you need?In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) Code here , Aug 2021

