Building Language Technologies by Machine Reading Grammars
funded by the NSF (2023-)
Project Description
Recent years have seen incredible advances in natural language processing (NLP) technologies, which now make it possible to perform numerous tasks through, with, or on language data. However, this progress has been limited to the handful of languages for which abundant data are available, because the neural models that facilitate the recent improvements are particularly data hungry. This work suggests that we should move away from the current data-inefficient learning paradigm, and instead attempt to also model languages by relying on the human mode of describing them: the grammar of each language. Put simply, we will aim to incorporate the grammars of languages, as written by linguists and treated as symbolic knowledge bases, in the process of training neural language models.
Concretely, this project will (1) build the necessary datasets to explore the meta-linguistic capabilities of large language models. Then, it will (2) explore ways to build LLMs for new languages by relying on grammars, similar to how a human learns a second language. Next, the proposed work aims at (3) making theoretical connections to various learning paradigms, and attempting to model the process of multilingual learning itself. Last, the project will (4) delve deeper into the errors potentially exhibited by language models. Additionally, the proposed research will be integrated into education through new teaching modules combining linguistics with natural language processing, promoting undergraduate research. The project will aim to extend its impact beyond the classroom through close collaboration with underserved language communities, aiming to build technologies according to the communities’ needs.
We present a comprehensive three-phase study to ex-amine (1) the cultural understanding of Large Multimodal Models (LMMs) by introducing Dalle Street, a large-scale dataset generated by DALL-E 3 and validated by hu-mans, containing 9, 935 images of 67 countries and 10 concept classes, (2) the underlying implicit and potentially stereotypical cultural associations with a cultural artifact extraction task, and (3) an approach to adapt cultural representation in an image based on extracted associations using a modular pipeline, Cultureadapt. We find disparities in cultural understanding at geographic sub-region levels with both open-source (LLaVA) and closed-source (GPT-4V) models on Dalle Street and other existing benchmarks, which we try to understand using over 18, 000 artifacts that we identify in association to different coun-tries. Our findings reveal a nuanced picture of the cultural competence of LMMs, highlighting the need to develop culture-aware systems.11Dataset and code are available: https://github.com/iamshnoo/crossroads
@inproceedings{mukherjee-etal-2025-crossroads,author={Mukherjee, Anjishnu and Zhu, Ziwei and Anastasopoulos, Antonios},booktitle={2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},title={Crossroads of Continents: Automated Artifact Extraction for Cultural Adaptation with Large Multimodal Models},year={2025},volume={},number={},pages={1755-1764},keywords={Cultural competence;Adaptation models;Computer vision;Codes;Computational modeling;Pipelines;Benchmark testing;Cultural differences;Continents;Artificial intelligence;cultural localization;cultural bias analysis;llm;multimodal;culture;dataset},doi={10.1109/WACV61041.2025.00178},issn={2642-9381},month=feb,}
2024
NAACL
A Study on Scaling Up Multilingual News Framing Analysis
Syeda Sabrina Akter, and Antonios Anastasopoulos
In Findings of the Association for Computational Linguistics: NAACL 2024 code here , Jun 2024
Media framing is the study of strategically selecting and presenting specific aspects of political issues to shape public opinion. Despite its relevance to almost all societies around the world, research has been limited due to the lack of available datasets and other resources. This study explores the possibility of dataset creation through crowdsourcing, utilizing non-expert annotators to develop training corpora. We first extend framing analysis beyond English news to a multilingual context (12 typologically diverse languages) through automatic translation. We also present a novel benchmark in Bengali and Portuguese on the immigration and same-sex marriage domains.Additionally, we show that a system trained on our crowd-sourced dataset, combined with other existing ones, leads to a 5.32 percentage point increase from the baseline, showing that crowdsourcing is a viable option. Last, we study the performance of large language models (LLMs) for this task, finding that task-specific fine-tuning is a better approach than employing bigger non-specialized models.
@inproceedings{akter-anastasopoulos-2024-study,title={A Study on Scaling Up Multilingual News Framing Analysis},author={Akter, Syeda Sabrina and Anastasopoulos, Antonios},editor={Duh, Kevin and Gomez, Helena and Bethard, Steven},booktitle={Findings of the Association for Computational Linguistics: NAACL 2024},month=jun,year={2024},address={Mexico City, Mexico},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.findings-naacl.260/},doi={10.18653/v1/2024.findings-naacl.260},pages={4156--4173},}
EMNLP
The LLM Effect: Are Humans Truly Using LLMs, or Are They Being Influenced By Them Instead?
Alexander Choi*, Syeda Sabrina Akter*, J.p. Singh, and Antonios Anastasopoulos
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024
Large Language Models (LLMs) have shown capabilities close to human performance in various analytical tasks, leading researchers to use them for time and labor-intensive analyses. However, their capability to handle highly specialized and open-ended tasks in domains like policy studies remains in question. This paper investigates the efficiency and accuracy of LLMs in specialized tasks through a structured user study focusing on Human-LLM partnership. The study, conducted in two stages—Topic Discovery and Topic Assignment—integrates LLMs with expert annotators to observe the impact of LLM suggestions on what is usually human-only analysis. Results indicate that LLM-generated topic lists have significant overlap with human generated topic lists, with minor hiccups in missing document-specific topics. However, LLM suggestions may significantly improve task completion speed, but at the same time introduce anchoring bias, potentially affecting the depth and nuance of the analysis, raising a critical question about the trade-off between increased efficiency and the risk of biased analysis.
@inproceedings{choi-etal-2024-llm,title={The {LLM} Effect: Are Humans Truly Using {LLM}s, or Are They Being Influenced By Them Instead?},author={Choi, Alexander and Akter, Syeda Sabrina and Singh, J.p. and Anastasopoulos, Antonios},editor={Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung},booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},month=nov,year={2024},address={Miami, Florida, USA},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.emnlp-main.1230/},doi={10.18653/v1/2024.emnlp-main.1230},pages={22032--22054},}
EMNLP
Back to School: Translation Using Grammar Books
Jonathan Hus, and Antonios Anastasopoulos
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing code here , Nov 2024
Machine translation systems for high resource languages perform exceptionally well and produce high quality translations. Unfortunately, the vast majority of languages are not considered high resource and lack the quantity of parallel sentences needed to train such systems. These under-represented languages are not without resources, however, and bilingual dictionaries and grammar books are available as linguistic reference material. With current large language models (LLMs) supporting near book-length contexts, we can begin to use the available material to ensure advancements are shared among all of the world‘s languages. In this paper, we demonstrate incorporating grammar books in the prompt of GPT-4 to improve machine translation and evaluate the performance on 16 topologically diverse low-resource languages, using a combination of reference material to show that the machine translation performance of LLMs can be improved using this method.
@inproceedings{hus-anastasopoulos-2024-back,title={Back to School: Translation Using Grammar Books},author={Hus, Jonathan and Anastasopoulos, Antonios},editor={Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung},booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing},month=nov,year={2024},address={Miami, Florida, USA},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.emnlp-main.1127/},doi={10.18653/v1/2024.emnlp-main.1127},pages={20207--20219},}
ACL
Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource Languages
Antonios Dimakis, Stella Markantonatou, and Antonios Anastasopoulos
In Findings of the Association for Computational Linguistics: ACL 2024 code here , Aug 2024
Multi-word expressions (MWEs) present unique challenges in natural language processing (NLP), particularly within the context of translation systems, due to their inherent scarcity, non-compositional nature, and other distinct lexical and morphosyntactic characteristics, issues that are exacerbated in low-resource settings.In this study, we elucidate and attempt to address these challenges by leveraging a substantial corpus of human-annotated Greek MWEs. To address the complexity of translating such phrases, we propose a novel method leveraging an available out-of-context lexicon.We assess the translation capabilities of current state-of-the-art systems on this task, employing both automated metrics and human evaluators.We find that by using our method when applicable, the performance of current systems can be significantly improved, however these models are still unable to produce translations comparable to those of a human speaker.
@inproceedings{dimakis-etal-2024-dictionary,title={Dictionary-Aided Translation for Handling Multi-Word Expressions in Low-Resource Languages},author={Dimakis, Antonios and Markantonatou, Stella and Anastasopoulos, Antonios},editor={Ku, Lun-Wei and Martins, Andre and Srikumar, Vivek},booktitle={Findings of the Association for Computational Linguistics: ACL 2024},month=aug,year={2024},address={Bangkok, Thailand},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.findings-acl.152/},doi={10.18653/v1/2024.findings-acl.152},pages={2588--2595},}
NAACL
Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction Tuning
Anjishnu Mukherjee, Aylin Caliskan, Ziwei Zhu, and Antonios Anastasopoulos
In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) code here , Jun 2024
Exploring the intersection of language and culture in Large Language Models (LLMs), this study critically examines their capability to encapsulate cultural nuances across diverse linguistic landscapes. Central to our investigation are three research questions: the efficacy of language-specific instruction tuning, the impact of pretraining on dominant language data, and the identification of optimal approaches to elicit accurate cultural knowledge from LLMs. Utilizing the GeoMLaMA benchmark for multilingual commonsense knowledge and an adapted CAMeL dataset (English-only) for evaluation of nuanced cultural aspects, our experiments span six different languages and cultural contexts, revealing the extent of LLMs’ cultural awareness. Our findings highlight a nuanced landscape: while language-specific tuning and bilingual pretraining enhance cultural understanding in certain contexts, they also uncover inconsistencies and biases, particularly in non-Western cultures. This work expands our understanding of LLMs’ cultural competence and emphasizes the importance of integrating diverse cultural perspectives in their development, aiming for a more globally representative and equitable approach in language modeling.
@inproceedings{mukherjee-etal-2024-global,title={Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction Tuning},author={Mukherjee, Anjishnu and Caliskan, Aylin and Zhu, Ziwei and Anastasopoulos, Antonios},editor={Duh, Kevin and Gomez, Helena and Bethard, Steven},booktitle={Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)},month=jun,year={2024},address={Mexico City, Mexico},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.naacl-long.355/},doi={10.18653/v1/2024.naacl-long.355},pages={6398--6415},}
AIES
Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis
Large Language Models (LLMs) perpetuate social biases, reflecting prejudices in their training data and reinforcing societal stereotypes and inequalities. Our work explores the potential of the Contact Hypothesis, a concept from social psychology for debiasing LLMs. We simulate various forms of social contact through LLM prompting to measure their influence on the model’s biases, mirroring how intergroup interactions can reduce prejudices in social contexts. We create a dataset of 108,000 prompts following a principled approach replicating social contact to measure biases in three LLMs (LLaMA 2, Tulu, and NousHermes) across 13 social bias dimensions. We propose a unique debiasing technique, Social Contact Debiasing (SCD), that instruction-tunes these models with unbiased responses to prompts. Our research demonstrates that LLM responses exhibit social biases when subject to contact probing, but more importantly, these biases can be significantly reduced by up to 40% in 1 epoch of instruction tuning LLaMA 2 following our SCD strategy.
@article{Raj_Mukherjee_Caliskan_Anastasopoulos_Zhu_2024,title={Breaking Bias, Building Bridges: Evaluation and Mitigation of Social Biases in LLMs via Contact Hypothesis},volume={7},url={https://ojs.aaai.org/index.php/AIES/article/view/31715},doi={10.1609/aies.v7i1.31715},number={1},journal={Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society},author={Raj, Chahat and Mukherjee, Anjishnu and Caliskan, Aylin and Anastasopoulos, Antonios and Zhu, Ziwei},year={2024},month=oct,pages={1180-1189},}
EMNLP
BiasDora: Exploring Hidden Biased Associations in Vision-Language Models
Existing works examining Vision-Language Models (VLMs) for social biases predominantly focus on a limited set of documented bias associations, such as gender-profession or race-crime. This narrow scope often overlooks a vast range of unexamined implicit associations, restricting the identification and, hence, mitigation of such biases. We address this gap by probing VLMs to (1) uncover hidden, implicit associations across 9 bias dimensions. We systematically explore diverse input and output modalities and (2) demonstrate how biased associations vary in their negativity, toxicity, and extremity. Our work (3) identifies subtle and extreme biases that are typically not recognized by existing methodologies. We make the **D**ataset **o**f **r**etrieved **a**ssociations (**Dora**) publicly available.
@inproceedings{raj-etal-2024-biasdora,title={{B}ias{D}ora: Exploring Hidden Biased Associations in Vision-Language Models},author={Raj, Chahat and Mukherjee, Anjishnu and Caliskan, Aylin and Anastasopoulos, Antonios and Zhu, Ziwei},editor={Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung},booktitle={Findings of the Association for Computational Linguistics: EMNLP 2024},month=nov,year={2024},address={Miami, Florida, USA},publisher={Association for Computational Linguistics},url={https://aclanthology.org/2024.findings-emnlp.611/},doi={10.18653/v1/2024.findings-emnlp.611},pages={10439--10455},}



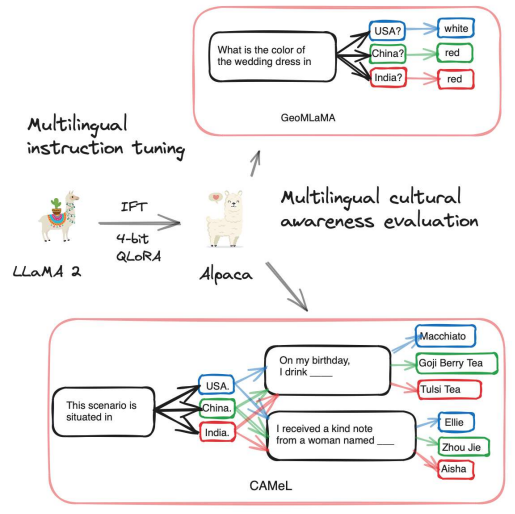 Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction TuningIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) code here , Jun 2024
Global Gallery: The Fine Art of Painting Culture Portraits through Multilingual Instruction TuningIn Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) code here , Jun 2024





